ABC
docz
Explore
Log in
Create new account
Download
Report
hobbies and interests
arts and crafts
pottery
Horizontal Code Transfer via Program Fracture and
Pub lishin g/Di strib
19-Slides - Breaks
ANNUAL REPORT 2011-2012
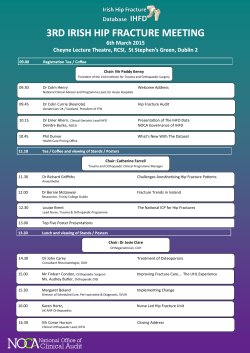
3rd irish hip fracture meeting 3rd irish hip fracture meeting
Physiotherapy Information Leaflet
Why do some falls result in fractures? An analysis of over 33,000 institutional falls Prue McRae , Satyan Chari
Contact Us Our Location
Head Comb Suite
this PDF form
Registration (Due September 30) Australian and New Zealand Society of Geriatric
© Copyright 2026
About abcdocz
DMCA / GDPR
Report