ABC
docz
Explore
Log in
Create new account
Download
Report
technology and computing
consumer electronics
camera and photo equipment
cameras and camcorders
cameras
How To Teach Stereoscopic Matching? (Invited Paper) Radim ˇS´ara
How to do the wiring of XM 300C, XD 312:
www.TabletMod.com This guide shows how to tailor the calibration manually to... Build. This is based on the Intuos4 Large assuming...
Guidance on how to complete our application form
PowerCheque How to Get Your ATM-Debit Card Tell a cashier or customer service
Handicap Manual Section 9-5 (How to Decide Ties In Handicap Competitions)
OTE-260013 How to adjust your Drag Racing Christmas Tree light settings
REVISITING GUIDED IMAGE FILTER BASED STEREO MATCHING AND SCANLINE
free 1 skill level
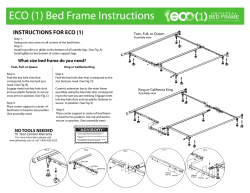
ECO (1) Bed Frame Instructions INSTRUCTIONS FOR ECO (1)
The Snuglet
This may or may not apply to you. Quite a... their employees give to Cru. We wanted you to...
© Copyright 2026
About abcdocz
DMCA / GDPR
Report