
QUESTION BANK COMPUTER ARCHITECTURE ORGANIZATION Q. What is Computer Architecture?
QUESTION BANK COMPUTER ARCHITECTURE ORGANIZATION Q. What is Computer Architecture? Ans. Computer Architecture : It is concerned with structure and behaviour of computer as seen by the user. It includes the information formats, the instruction set, and techniques for addressing memory of a computer system is concerned with the specifications of the various functional modules, such as processors and memories and structuring them together into a computer system. Q. What is Computer Organisation? Ans. Computer Organisation: It is concerned with the way the hardware components operate and the way they are connected together to form the computer system. The various components are assumed to be in place and the task is to investigate the organisational structure to verify that the computer parts operate. Q. What is the concept of layers in architectural design? Ans. The concepts of layers in architectural design are described as below: Nitisha Garg Asst. Prof. (GIET) 1. Complex problems can be segmented into smaller and more manageable form. 2. Each layer is specialized for specific functioning. 3. Upper layers can share the services of a lower layer. Thus layering allows us to reuse functionality. 4. Team development is possible because of logical segmentation. A team of programmers will build. The system and work has to be sub-divided of along clear boundaries. Q. Differentiate between computer architecture and computer organisation. Ans. Difference between computer organisation: computer architecture and Q. Draw top leveled view of computer components. Ans. Computer organization includes emphasis on system components, circuit design, logical design, structure of instructions, computer arithmetic, processor control, assembly programming performance enhancement. and methods of Diagram : Top level view of computer component Q. Write typical architecture. physical realisations of Ans. Important types of bus architecture used in a computer system are: (i) PCI bus (ii) ISA bus (iii) Universal serial bus (USB) (iv) Accelerated graphics port (AGP). PCI bus : PCI stands for peripheral component interconnect It was developed by Intel. Today it is a widely used bus architecture. The PCI bus can operate with either 32 bits or 64 bit data bus and a full 32-bit address bus. ISA Bus: ISA stands for industry standard Architecture. Most Pcs contain ISA slot on the main board to connect either an 8—bit ISA card or a 16—bit ISA card. USB : It is a high speed serial bus. It has higher data .transfer rate than that of a serial port fashion. Several devices can be connected to it in a daisy chain. AGP: It is a 32—bit expansion slot or bus specially design for video card. Q. What is Channel? Ans. A channel is one of data transfer technique. This technique is a traditionally used on mainframe computers and also becoming more common on smaller systems. It controls multiple high speed devices. It combines the features of multiple and selector channels. This channel provides a connection to a number of High speed devices. Q. Draw the machine architecture of 8086. Ans. Q. Explain about the computer Organisation. Ans. Computer organisation is concerned with the way the hardware components operate and the way they are connected together to form the computer system. The various components are assumed to be in place ad task is to be a organisational structure. IL includes emphasis on the system components, circuit design, logical design, structure of instruction, computer arithmetic, processor control, assembly programming and methods of performance enhancement. Q. Explain the significance of layered architecture Ans. Significance of layered architecture: In layered architecture, complex problems can be segmented into smaller and more manageable form. Each layer is specialized for specific functioning. Team development is possible because of logical segmentation. A team of programmers will build. The system, and work has to be sub-divided of along clear boundaries. Q. HOw can you evaluate of processor architecture. the performance Ans. In processor architecture, there is no. of processor where 8086 and 8088 has taken an average of 12 cycles to execute a single instruction. XXX286 and XX386 are 4.5 cycles per instruction XX486 and most fourth generation intel compatible processor such as DMD X 85, drop the rate further, about 2 cycles per instruction. Latest processor are pentium pre, pentiom 11/111/4/celeron and Athlon/ Duress : These P6 and P7 processor S can execute as many as three or more instructing per cycle. Q.Explain metrics. the various types of performance Ans. Performance metrics include availability, response time, Channel capacity, latency, Completion time. Q. Write a short note on “cost/benefit in layered Architecture design.” Or H/W and S/W partitioning design: Ans. One common architectural design pattern is based on layers. Layers are an architectural design pattern that structures applications can be decomposed into groups of subtasks such that each of subtasks is at a particular level of abstraction. A large system requires decomposition. One way to decompose a system is to segment it into collaborating objects. Then these objects are grouped to provide related types of services. Then these groups are interfaced with each other for inter communication and that results in a layered architecture. The traditional 3— tier client server model, which separates application functionality into three distinct abstractions, is an example of layered design. The three layers include data, business rules and graphical user interface. Similar is the 051 seven layer networking model and internet protocol stack based on layered architecture. The following are the benefits of layered architecture 1. Complex problems can be segmented into smaller and more manageable form. 2. Team development is possible because of logical segmentation. A team of programmers will build the system, and work has to be sub-divided along cler boundaries. 3. Upper layers can share the services of a lower layer. Thus layering allows us to reuse functionality. 4. Each layer is specialized for specific functioning. Late source code changes should not ripple through the system of layered architecture. The similar responsibilities should be grouped to help understand ability and maintainability. Layers are implemented as software to isolate each disparate concept or technology. The layers should isolate at the conceptual level. By isolating the database from the communication code, we can change one or the other with minimum impact on each other. Each layer of the system deals with only one concept. The layered architecture can have many beneficial effects on application, if it is applied in proper way. The concept of architecture is simple and easy to explain to team members and so demonstrate where each object’s role fits into the team. With the use of layered architecture, the potential for reuse of many objects in the system can greatly increased. Q. Write a note on. (a) VLIW Architecture (b) Super scalar processor. Ans. (a) Very long instruction word (VLIW) is a modification over super scalar architecture VLIW architecture implements instruction level parallelism (ILP). VLIW processor fetches very long instruction work having several operations and dispatches it is parallel execution to different functional units. The width of instruction varies from 128 to 1024 bits. VLIW architecture offers static scheduling as super scalar architecture offers dynamic (run time) scheduling. That means view offers a defined plan of execution of instruction by functional units. Due to static scheduling, VLIW architecture can handle up to eight operations per clock cycle. While super scalar architecture can handle up to five operations at a time. VLIW architecture needs the complete knowledge of Hardware like processor and their functional units. It is fast but inefficient for object oriented and event driver programming. In event driven and object oriented programming super scalar architecture is used. Hence view and super scalar architecture are important in different aspects. (b) Super Scalar Processor : The scalar processor executes one instruction on one set of operands at a time. The super scalar architecture allows the execution of multiple instructions at the same time. In different pipelines. Here multiple processing elements are used for different instruction at the same time. Pipelining is also implemented in each processing elements. The instruction fetching units fetch multiple instructions at a time from cache. The instruction decoding unit check the independence of these instruction so that they can be executed in parallel. There should be multiple execution units so that multiple instructions can be executed at same time. The slowest stage among fetch, decode and execute will determine the overall performance of the system. Ideally these three stages should be equally fast. Practically execution stage in slowest and drastically affect the performance of system. Q. Write a note on following: (i) Pentium Processor - (ii) Server System Ans. (i) Pentium processor : Pentium processor with super scalar architecture came as modification of 80486 and 8086. It is based on CISC and uses two pipelines for integer processor so that two instructions are processed simultaneously one pipeline will have same condition then another is compared with hardware 80486 processor had only adder in one chip floating point unit. One the other side Pentium processor is having adder, multiplier and divide in on chip floating point unit. That means Pentium processor can do the multiplication and division fastly. The separate data and code cache of 8KB exits on chip. Dual independent bus (DIB) architecture divides the bus as front side and backside bus. Backside Bus transfer the data from L2 Cache to CPU and viceversa. Front side bus is used to transfer the data from CPU to main memory and to other components of system. Pentium processor user write back policy for cache data, while 80486 uses write through policy for cache data. The detail other common types of processor are AMD and cyrix Although these two types of processor are less powerful as compared to Pentium Processor. (ii) Server System : System is formed as server or client depending upon the software used in that machine suppose window 2003 server operating system is installed on machine, that machine will be termed as sever. If on the same machine Window 95 is installer that machine is termed as client. Although server machine uses specialised hardware meant for faster processing server provides the service to other machine called client attached to server. Different types of servers are Network server, web server, database server, backup server. Sever system is having powerful computing power, high performance and higher clock speed. These system are having good fault tolerance capability using disk mirroring, disk stripping and RAID concepts. These system have back up power supply with hot swap. IBM and SUN servers are providing the different server of server for different use. Q. What is principle of performance and scalability in Computer Architecture. Ans. Computer Architecture have the good performance of computer system. It is implementing concurrency can enhance the performance. The concept of concurrency can be implemented as parallelism or multiple processors with a computer system. The computer performance is measured by the total time needed to execute application program. Another factor that affects the performance is the speed of memory. That is reason the current technology processor is having their own cache memory. Scalability is required in case of multiprocessor to have good performance. The scalability means that as the cost of multiprocessor increase, the performance should also increase in proportion. The size access time and speed of memories and buses play a major role in the performance of the system. Q. What is evaluation of computer architecture? Ans. Computer Architecture involves both hardware organisation and programming software requirements. At seen by an assembly language programmer, computer architecture is abstracted by an instruction set, which includes opcode (operation codes), addressing modes, register, virtual memory, etc. from the hardware implementation point o1 view, the abstract machine is organised with CPUs, caches, buses, microcode, pipelines physical memory etc. Therefore, the study of architecture covers both instruction set architectures and machine implementation organisation. Over the past four decades, computer architecture has gone through evolution rather than revolutionary changes, sustaining features are those that were proven performance delivers. We started with Neumann architecture built as a sequential machine executing scalar data. The sequential Computer was improved from bit survival to word-parallel operations, and from fixed point to floating point operations. The von Neumann architecture is slow due to sequential execution of in programs. Q. What is parallelism and pipelining in computer Architecture? Ans. LOOK AHEAD, PARALLELISM , AND PIPELINING IN COMPUTER ARCHITECTURE Look ahead techniques were introduced to prefetch instruction in order to overlap I/F (Instruction fetch/decode and execution) operations and to enable functional parallelism. Functional parallelism was supported by two approaches : One is to use multiple functional units simultaneously and the other is to practice pipelining at various processing levels. The later includes pipelined instruction execution, pipelined arithmetic computation, and memory access operations. Pipelining has proven especially attractive in performing identical operations repeatedly over vector data strings. Vector operations were originally carried out implicitly by software controlled looping using scalar pipeline processors. Q.How many cycles are required to execute per instruction for 8086, 8088, intel 286, 386, 486, pentium, K6 series, pentium 11/111/4/cebron, and Athion/Athion XP/Duron? Ans. The time required to execute instructions for different processors are as follows: • 8086 and 8088 : It has taken an average of 12 cycles to execute a single instruction. • 286 and 386 : It improve this rate to about 4.5 cycles per instruction. 486 : The 486 and most other fourth generation intel-compatible processors, such as the DMD 5 x 86, drop the rate further, to about 2 cycles per instruction. • Pentium, K6 Series,: The pentium architecture and other fifth generation intel compatible processors, such as those from AMD and cyrix, include twin instruction pipelines and other improvements that provide for operation at one or two instruction per cycle. • Pentium pro, pentium II,fIII/4/celeron, and Athion/Athlon XP/Duron : These P6 and P7 (Sixth and Seventh generation) processors can execute as many as three or more instructions per cycle. Q. What is cost/benefit in layered Architecture design? Or Write functional view of computer which are the possible computer operational. Ans. A larger system require decomposition. Only way to decompose a system is to segment it into collaborating objects. These objects are grouped to provide related types of services. Then these groups are interfaced with each other for inter communication and that results in a layered architecture. The following are benefits of layered architecture 1. Complex problems can be segmented into smaller and more manageable form. 2. Team development is possible because of logical segmentation. A team of programmes will build the system, and work has to be subdivided along clear boundaries. 3. Upper layer can share the services of a lower layer. Thus layering allows us to reuse functionalities. 4. Each layer is specialized for specific functioning. 5. Late source code changes should not ripple through the system because of layered architecture. 6. Similar responsibilities should be grouped to help under stability and maintainability. 7. A message that moves downwards between layers is called request. A client issues a request to layer. I suppose layer I cannot fulfill it, then it delegates to layer J—1. 8. Messages that moves upward between layers are called notifications. A notification could start at layer I. Layer I then formulates and sends a message (notification) to layer j +1. 9. Layers are logical placed to keep information caches. Requests that normally travel down through several layers can be cached to improve performance. 10. A system’s programming interface is often implemented as a layer. Thus if two application or inter application elements need to communicate placing the interface responsibilities into dedicated layers. Can greatly simplify the task and make them more easily reusable. Layers are implemented as software to isolate each disparate concept or technology. The layers should isolate at conceptual level. By isolating the data base from the communicate code, we can change one or the other with minimum impact on each other. Each layer of the system deals with only one concept. The layered architecture can have many beneficial effects on application, if it is applied in proper way. The concept of the architecture is simple and easy to explain to team member and so demonstrate where each objects role fits into the team. With the use of layer architecture, the potential for reuse of many objects in the system can be greatly increase. The best benefit of this layering is that .malws it easy to divide work along layer boundaries is easy to assign different teams or individuals to work of coding the layers in layered architectures, since the interfaces are identified and understood well in advance of coding. Performance of system is measure of speed, throughput. Higher is cost involves for manufacturing of computer, High is the performance as shown in figure. Personal computer is cheapest in term of cost among server, mainframe and super computer. Super computer is the costliest one. Same is the hierarchy for the performance of the system. Most of simple applications can be executed on personal computers. For faster processing server, mainframe and super computing are used. Sometimes using too much I/O devices increases the cost but decreasing the performance in personal computer. That is termed as diminishing the performance with increase in the cost/sublinear diminishing, Like SCSI adopter increase the cost of system but that also increases the performance of server as termed as super linear economy in case of server. The ideal case is termed as linear representation where performance increases in the same proportion of cost. These are represented in graph shown in figure. Q. Define ASCII code. Ans. ASCII stands for American Standard code for Information Interchange. It is greatly accepted standard alphanumeric code used in microcomputers. ACII of bit code represents 2 128 different characters. These character represent 26 upper case letter (A to Z), 26 lowercase letters (a to z), 10 numbers (0 to 9), 33 special characters, symbols and 33 control characters. ASCII 7-bit code is divided into two portions. The left most 3-bits portion is called zone bits and the 4-bit portion on the right is called the numeric bits. ASCII 8-bit version can be used to represent a maximum of 256 characters. Q. What is EBCDIC? Ans. EBCDIC stands for extended Binary coded Decimal interchange code. A standard code that uses 8-bits to represent each of 256 alphanumeric characters Extended Binary coded Decimal interchange code is an 8-bit character encoding used on IBM mainframes EBCDIC having eight bits code divided into two parts. The first four, bits (on the left) are called zone and represent the category of the character and the last four bits (on the right) are called the digits and identify the specific character. Q. Write a short note on: (i) Excess 3 (ii) Gray code. Ans. Excess —3 : Excess 3 is a non-weighted code used to express decimal numbers. The code derives its name from the fact that each binary code is the corresponding 8421 code plus 0021 (3). Excess representation of decimal numbers 0 to 9 Example Gray Code : Gray coding is an important code and is known for its speed. This code is relatively free from the errors. In binary coding or 8421 BCD, counting from 7(0111) to 8(1 000) requires 4-bits to be changed simultaneously. Gray coding avoids this by following only one bit changes between subsequent numbers. Q. What is shift register in digital computer. Ans. Shift registers are the sequential logic circuit used to shift the data from registers in both directions. Shift registers are designed as a group of flip-flops connected together so that the output from one flip-flop becomes the input to the next flip-flop. The flip-flop are driven by a common clock signals and can be set or reset simultaneously. Shift registers can be connected to form different type of counters. Q. Which logic name is known as universal logic? Ans. NAND logic and NOR logic gates are universal logic. It is possible to implement any logic expression by NAND and NOR gates. This is because NAND and NOR gates can be used to perform each of Boolean operations INVERT, AND and OR. NAND is same as AND gate symbol except that it has a small circle at output. This a small circle represents the universal operations. Q. What is time known when D-input of D-FF must not change after clock is applied? Q. Addition of (1111)2 to 4-bit binary ‘A’ results: (1) incrementing A (ii) Addition of (F)11 (iii) No change (iv) Decrementing A. Ans. Addition of (F)H Q. Register A holds the 8-bit binary 11011001. Determine the B operand and the logic microoperation to be performed in order to change the value in A to: Q. An 8-bit register R contain the binary value 10011100 what is the register value after an arithmetic shift right? Starting from the initial number 10011100, determine the register value after an arithmetic shift left, and state whether there is an overflow. Q. Write an algorithm of summation of a set of numbers. Ans. This sum is a sequential operation that requires a sequence of add and shift micro-operation. There is addition of n numbers can be done with micro-operation by means of combinational circuit that performs the sum all at once. An array addition can implemented with a combinational circuit. The argend and addend are i.e. a0, a1, a2, a3 ...a. There are following steps of summation of a set of number. Step 1. There is n-array, numbers which are a1, a1, a2 .. .a so the result is in sum. Step 2. Input of a0, a2, a3,.. .a1 are given the combinational logical circuit. It shows the result. Step 3. The output is takens in sum and some time, a carry is produced. Step 4. A carry is put in the carry flag. The total result of sum is stored in SUM and carry is stored in CARRY. Q. Simplify the following Boolean functions using three variable map in sum of product form. 1.f(a,b,c)=(1,4,5,6,7) 2. f.(a, b, c) = E (0, 1, 5, 7) 3. f (a, b, c) = E (1, 2, 3, 6, 7) 4. f (a, Li, c) = (3, 5, 6, 7) 5.f(a, Li, c) Y(O, 2, 3,4,6) Ans. Q. Simplify the ( a, b, c, d) = (0,1,2,5,8,9,10) Boolean functions using four variable map in sum of product and product of sum form. Verify the results of both using truth table. Ans. Sum of Product (SOP) f(a,b,c,d) =E(O,1,2,5,8,9,1O) These are two 4-bit input A(A3, A2, A1, A0) B (B3, B2, B1, l3) and a 4-bit output D (D3, D2,D, D0). The four inputs form A(A3, A2, A1, A0) are applied directly to X (X3 X2, X1, X0) inputs of full adder. The four inputs from B’ (B B2 B1 B0) are connected to data input I of four multiplexer. The logic input 0 is connected to data input 12 oi four multiplexers. The logic input I is connected to data input 13 of four multiplexers. One of the four inputs of multiplexer as output is selected by two selection lines S0 and S1. The outputs from all four multiplexers are connected to the Y (Y3 Y2 Y, Y0) inputs of full adder. The input carry Cm is applied to the carry input of the full adder FAI. The carry generated by adder is connected to next adder and finally cout is generated. The output generated by full adder is represented by expression shown ahead. Q. Explain the De-Morgan's theorems. De-Morgan theorem is applicable to n number of variable. Where n can have value 2, 3, 4 etc. De-Morgan theorem for three variables will be shown ahead. (A÷B+C)’ =A’.B’.C’ (A.B.C)’ A’+B’+C’ To prove the following identity [(A’ + C). (B + D’)]’ = A. C’ + B’. D Let x = [(A’ + C). (B + D’)]’ (A’ + C’). (B + D’)’ [De-Morgan theorem] = (A”. C’) + (B’. D”) [De-Morgan theorem] = A. C’ + B’. D. The truth table for the second expression is given ahead. The equivalent between the entries in column (A’ + B’) and (A. B’). Prove the 2nd theorem. Q. 27. What is universality of NAND and NOR Gates? Ans. It is possible implement any logic expression using only NAND gates. This is because NAND gate can he used to perform each of the Boolean operations INVERT, AND and OR. NANI) is the same as the AND gate symbol except that it has a small circle at the output. This small circle represents the inversion operation. Therefore the output expression of the input NAND gate is X = (A.B)’ The INVERT, AND OR gates have been constructed using NAND gates. NOR is the same as OR gate symbol except that it has a small circle at the output The small circle represents the inversion operation The Boolean expression and logic diagram of two input NOR gate is described ahead NAND and NOR are universal gate. It can implement any logic gate or circuit. Q. Register a is having S-bit number 11011001. Determine the operand and logic micro-operation to be performed in order to change the value in A to. (i) 01101101 (ii) 11111101 (iii) Starting from an initial value R = 11011101, determine the sequence of binary values in R after a logical shift left, followed by circular shift right, followed by a logical shift right and a circular shift left. Ans. (1) 11011001 A Register 10110100 B Register 01101101 A register after operations. The selective complement operation complements the bits in register A where there is 1 in the corresponding bit of register B. This does not affect the bit value in A. Where there are 0 in the corresponding bit of register B. (ii) 11011001 A register 00100100 B register 11111101 A register after operation. The selective set operation sets the bit in register A to 1. Where there is I in corresponding bit of register B. This does not affect the bit value in. A where there are 0 in corresponding bit of register B. (iii) 11011101 R register 10111010 R register after logical shift left 01011101 R register after circular shift right 00101110 R register after logical shift right 01011100 R register after circular shift left. Q. Design a 4-bit common bus to transfer the contents of one register to other. Solution. Common bus is a mean for transferring the information from one register to other. The 4-bit common bus is constructed with four multiplexers. The bus is not only used for transferring the information from register to register but also used for transfer information from register to memory, memory to register and memory to memory. The number of multiplexer are four because there are 4bits in each register used in the common bus. Moreover there are four registers named register A, register B, register C and register D. The size of each multiplexer is 4 1 because there are four register. There are two selection lines S and S in the 4 x 1 multiplexer. These multiplexers select one of register and its contents are placed on the common bus. The register is selected as shown in function table. Suppose the selection line S1 =00 that means the selection line has selected register A. A0 the least significant bit of register A is selected by MUX 1, A, the second least significant bit of register A is selected by MUX2, A2 the third least significant bit of register A is selected by MUX3 and A3, the most significant bit of the register A. A is selected by MUX4. Because the value of selection lines in each multiplexer is S1S0 = 00. The A1, A2 and A.3 have not connected to MUX2, MUX3 and MUX4 because that will make the diagram to be visually complicated. In Actual A1, A2 and A3 have been connected to MUX2, MUX3 and MUX4. Also C1, ‘C2 and C3 have been connected to MUX 2, MUX3 MUX4. That means ope bit data is selected by each multiplexer and is transferred to common bus. Similarly whee selection S1 5o — that means the register B is selected. The contents of register B will appear on common bus. Similarly when selection S. S0 10, that means the register D is selected. The contents of register B will appear on common bus. Similarly when selection S1 S0—li, that means the register D is selected. The contents of register will appear on common bus. Q. Design 4-bit arithmetic circuit that implements eight arithmetic operations. Ans. 4-bit arithmetic circuits constitute of four multiplexer of size 4 x and four full adders as shown in Figure 1. The required arithmetic micro-operation can be performed by the combination of selection lines So, S1 and C. 1. When S1 S0 = 00, 13 input 0, How multiplexers are selected as output B(B3, B2, B1, B0) If Cm 0 the output D = A + B (Add). If Cm =1, the output D A + B + C (Add with carry). 2 When S1 S = 01, I, input of four multiplexers are selected as output B’ (B; B2 B1 B0). If cm =6the output D = A+ B’ (substract with Borrow). If C1n 1, the output D = A + B’ + 1 (Substract). These are two 4-bit input A(A3, A2, A1, A0) B (B3, B2, B1, B0) and a 4-bit output D (D3, D21D, D0). The four inputs form A(A3, A2, A1, A0) are applied directly to X (X3 X2, X1, X0) inputs of full adder. The four inputs from B’ (B; B; B1 B) are connected to data input 13 of four multiplexer. The logic input 0 is connected to data input ‘2 of four multiplexers. The logic input I is connected to data input 13 of four multiplexers. One of the four inputs of multiplexer as output is selected by two selection lines S0 and S1. The outputs from all four multiplexers are connected to the Y (Y3 Y2 Y, Y0) inputs of full adder. The input carry Cm is applied to the carry input of the full adder FAI. The carry generated by adder is connected to next adder and finally cout is generated. The output generated by full adder is represented by expression shown ahead. D = X + y + C1 3. When S1 S0 = 10, 12 input of four multiplexer are selected as output (0000). If Cm = 0, the output D = A (transfer A), If Cm =1, the output D = A +1 (increment). 4. When S1S0 =11, 13 input of four multiplexers are selected as output (1111) is equivalent to the 2’s complement of 1. (2’s complement of binary 0001 is 1111). That means adding 2’s. Complement of I to A is equivalent to A - 1. If Cm =1, the output D A (transfer A). Transfer A micro operation has generated twice. Hence there are only seven distinct micro-operations. Q. Briefly explain instruction format. Ans. An instruction contain number of bits in the so that it is being to perform specific operation. Generally an instruction is divided into three fields Addressing mode: It specifies that how the operands are accessed in an instruction. Operation code (O):This field specifies the operation that is performed in the operand. Operand : It specifies the data on which operation is performed. Q. What is instruction pipelining? Ans. An instruction pipeline reads Consecutive instruction from memory previous instructions are being executed in other segments Pipeline processing can occur not only in data stream but in the instruction stream as well. This causes the instruction fetch and execute phases to overlap and perform simultaneous. The pipeline must be emptied and all instructions that have been read from memory after the branch instruction must be discarded. Q. What is RISC and CISC? Ans. RISC : It means Reduced instruction set computing. RISC machine use the simple addressing mode. Logic for implementation of these instructions is simple because instruction set is small in RISC machine. CISC: It means complex instruction set computing. It uses wide range of instruction. These instructions produce more efficient result. It uses the micro programmed control unit when RISC machines mostly uses hardwired control unit. It uses high level statement. It is easy to understand for human being. Q. Differentiate between RISC and CISC. Ans. Difference between RISC and CISC are given below: 1.It means Reduced Instruction set computing. 2.It uses hardwired control unit. 3.RISC requires fewer and limited instructions 4.Example of RISC processors are BM2PO,. SPARC from SO p-ticrosoft ycm, power PC and PA- RISC. —. CISC: It means complex instruction set computing. It uses micro programmed control unit. ClSC requires wide range of instructions. These instructions produce more efficient results. The example of CISC processor are IBM Z and digital equipment corporation VAX computer. Q. What is super pipelining? Ans. Pipelining is the concept of overlapping of multiple instructions during execution time. Pipeline splits one task into multiple subtasks. These subtasks of two or more different tasks are executed parallel by hardware unit. The concept of pipeline can be same as the water tab. The amount of water coming out of tab in equal to amount of water enters at pipe of tab. Suppose there are five tasks to be executed. Further assume that each task can be divided into four subtasks so that each of these subtasks are executed by one state of hardware. The execution of these five tasks is super pipe thing. Q. Explain about RISC processors. Ans. RISC means Reduced instruction computing. It has fewer and limited number instruction Earlier RISC processors do not have port for floating-point data But the current technology processors suit the float data type. It consume less power and are having high performance. RISC processor or systems are more popular than CISC due to better performance. It mostly use the hardwired control unit. RISC machines uses load and store. That means only load and store instruction can access the memory. This instructions operate on registers. Q. Explain micro programmed control. Ans. Micro programming is the latest software concept used in designing the control Unit. This is the concept controlling the sequence of micro operation computer. The operations are performed on data to read inside the registers are called micro operations. Micro programming is the concept for generating control signals using programs, These programs are called micro programs which are designed in control unit. Q. Explain pipelining in CPU design? Ans. Pipelining is a technique of decomposing a sequential process into sub-operations, with each subprocess being executed in a special dedicated segment that operates concurrently with all other segments A pipeline is a collection of processing segments through which binary information which is deforms partial processing dictated by the way the task is partitioned. The result obtained from the computation in each segment is transferred to next segment in the pipeline. The final result is obtained after the data have passed through all segments. Q Write any six characteristics of RISC. or Explain the important features of RISC based system architecture. Ans. There are following characteristics of RISC. 1. RISC machines require lesser time for its design implementation. 2. RISC processor consume less power and clock cycle. 3. RISC instructions are executed in single clock cycle, while most of CISC requires more than one clock cycle. 4. RISC system are more popular. L, 5. The current technology RISC processors support the floating point data type. 6. RISC machines mostly uses hardwired control unit. Q. What is SIMD Array processor? Ans. A SIMD array processor is a computer with multiple processing units operating in parallel. The processing unit are synchronised to perform the same operation under the control of common control unit, thus providing a single instruction stream, multiple data stream (SIMD) organization. Q. How pipelining would improve the performance of CPU justify. Ans. Non-pipeline unit that performs the same operation and takes a time equal to (time taken to complete each task). The total time required for n tasks is n t. The speed up of a pipeline processing over an equivalent non-pipeline processing is defined by the ratio As the number of tasks increases, n becomes much larger than k — 1, and K + n — I approaches the value of n, where K is segments of pipeline and Ip is time used to execute n tasks. Under this condition, the speed up becomes. The time it takes to process a task is the same in the pipeline and non pipeline circuits. There if t = kt speed reduces to Maximum speed that a pipeline can provide is K, where K is number of segments in pipeline. Speed of pipeline process is improved the performance of C.P.U. To clarify the meaning of improving the performance of C.P.U. through speed up ratio, consider the following numerical example. Let the time it takes to process sub operation in each segment be equal to 20 ns. Assume that the pipeline k 4 segments and executes n 100 tasks in square. The pipeline system will take (k + n — 1) t = (4 + 99) 20 = 2060 ns to complete. Assuming that t = kt = 4 x 20 = 80ns, a non-pipeline system requires nktp = 100 x 80 8080 ns to complete 100 tasks. The speed up ratio is equal to 8000/2060 88. As the number of tasks increase, the speed up will approach 4, which is equal to the number of segment in pipeline. It we assume that = 60ns, then speed up become=60/3. Q. Compare and contrast super pipelined machine and super scalar machines. Ans. Super pipelined machine : Pipelining is the concept overlapping of multiple instruction during execution time. Super of pipelining splits one tasks into multiple subtasks. These subtasks of two or more different tasks are executed parallel by different hardware units. It overlaps the multiple instructions in execution. The instruction goes through the four stages during execution phase. 1. Fetch an instruction from memory (Fl). 2. Decode the instruction (DI). 3. Calculate the effective address (EA). 4. Execute the instruction (LI). Fig. Space time diagram Super scalar processor/Machine : The scalar machine executes one instruction one set of operands at a time. The super scalar architecture allows on the execution of multiple instruction, at the same time in different pipeline. Here multiple processing elements are used for different instruction at the same time. Pipeline is also implemented in each processing elements. The instruction fetching units fetch multiple instructions at a time from cache. The instruction decoding units check the independence of those instructions at a time from cache. There should be multiple execution units so that multiple instructions can be executed at the same time. The slowest stage among fetch, decode and execute will determine the overall performance of system. Ideally these three stages should be equal fast. Q. Give the comparison between and examples of hardwired control unit and micro programmed control unit. Ans. There are two major types of control organisation (a) Hardwired control. (b) Microprogrammed control. In Hardwired organisation, the control logic implemented with gates, flip-flops, decoders. It has the advantage that it can be optimised to produce a fast mode of operation In microprogrammed organisation, the control information is stored in a control. The control memory is programmed to initiate the required sequence of micro operations. A hardwired control; as the name implies, requires changes in the wiring among the various components if the design has to be modified or changed. In the micro programmed control, any required changes or modifications can be done by updating the microprogram in control memory. A hardwired control for the basic computer is presented here. Difference between hardwired control programmed control are given below: and micro- Q. What do you understand by instruction cycle, machine put acknowledgment. Fetch cycle, cycle, inter Ans. Fetch cycle : The sequence counter is initialized to 0. The program counter (PC) contains the address the first instruction of a program under execution. The address of first instruction from PC is loaded into the address register (AR) during first clock cycle (To). Then instruction from memory location given by address register is loaded into the instruction register (IR) and the program counter is incremented to the address of next instruction in second clock cycle (TL). These microoperations using register transfer is shown as Instruction cycle: A program in computer consists of sequence of instructions. Executing these instructions runs the program in computer. Moreover each instruction is further divided into sequence of phases. The concept of execution of an instruction through different phases is called instruction cycle. The instruction is divided into sub phases as specified ahead— 1. First of all an instruction in fetched (accessed) from memory. 2. Then decode that instruction. 3. Decision is made for memory or register or I/O reference instruction. In case of memory indirect address, read the effective address from the memory. 4. Finally execute the instruction. Machine cycle: Machine includes following Hardware components. 1. A memory unit with 4096 words of 16 bits each. 2. Nine registers. 3. Seven flip-flops. 4. Two decoders : a 3 x 8 operation recorder and a 4 x 16 timing decoder. 5. 16-bit common bus. 6. Control logic gates. 7. Adder and logic circuit connected to the input of AC. The memory unit is a standard component that can be obtained readily from a commercial source. Interrupt Acknowledgment : The programmed controlled procedure is to external device inform the computer when it is ready for transfer. In the meantime the computer can be busy with other tasks. This type of transfer uses interrupt facility. The interrupt enable flipflop can be set and cleared with two instructions. When flip-flop is cleared with two instruction. When flip-flop is cleared to 0, the flags cannot interrupts computer when flip-flop is set to 1, the computer can be interrupted. This is way of interrupt acknowledge to C.P.U. and memory. Q. What is meant by super scalar processor? Explain the concept of pipelining in superscalar processor? Ans. The scalar processor executes one instruction on one set of operands at a time. The super scalar architecture allows the execution of multiple instructions at the same time in different pipelines. Here multiple processing elements are used for different instruction at same time. Pipeline is also implemented in each processing elements. The instruction fetching units fetch microinstruction at a time from cache. The instruction decoding unit checks the independence of these instructions so that they can be executed in parallel. There should be multiple execution units so the multiple instructions .can be executed at the same time. The slowest stage among fetch, decode and execute will determine the performance of the system. Ideally these three stages should be equally fast. Practically execution stage in slowest and drastically affect the performance of system. Pipeline overlaps the multiple instructions in execution. The instruction goes through the four stages during the execution phase. 1. Fetch an instruction from memory (Fl) 2. Decode the instruction (DI) 3. Calculate the effective address (EA) 4. Execute the Instruction (El). In space-time diagram above, five instructions are executed using instruction pipeline. These five instructions are executed in eight clock cycles. Each instruction had been through four stages. Although the various stages may not be of equal duration in each instruction. That ma result in waiting at certain stages. Q. Compare the instruction set Architecture is RISC and CISC processor in the instruction formats, addressing modes and cycle per instruction. (CPI) Ans. RISC Architecture involves an attempt to reduce execution time by simplifying the instruction set of the computer. The major characteristics of a RISC processor are: 1. Relatively few instructions. 2. Relatively few addressing modes. 3. Memory access limited to load and store instructions. 4. All operations done with in registers of the CPU. 5. Fixed length, easily decoded instruction format. 6. Single Cycle instruction execution. 7. Hardwired rather than micro programmed control. The small set of instructions of a typical RISC processor consists mostly of register to register operations, with only simple load and store operations for memory access. The Berkely RISC is a 82-bit integrated circuit CPU. It supports 32-bit addresses and either 8-, -16, or 32-bit data. It has a 32-bit instruction format and a total of 31 instructions. There are three basic addressing modes register addressing, immediate operand and relative to PC addressing for branch instructions. CISC Processor : The major characteristics of CISC architecture are: 1. A large member of instructions-typically from 100 to 250 instructions. 2. Some instructions that perform specialised tasks and are used in frequently. 3. A large variety of addressing nodes - typically from 5 to 20 different modes. 4. Variable-Length instruction formats. 5. Instruction that manipulate operands in memory. Q. What cause of processor pipeline to be under pipelined? Ans. The processor may have more than one functional unit. All these functional unit works under same control unit. Here the instructions are executed sequentially but can be overlapped during execution stages using pipelines. SISD computer executes one instruction on single data item at a time. This means its implementation is only for uniprocessor systems. There is a single control and single execution unit. SIMD computer executes one instruction on multiple data items at a time. This concept is implemented in vector or array processing and multimedia extension (MMX) in pentium. This means it is implemented in multiprocessor system. Here all processor receives the same instruction from control unit and implement it on different data items. There is single control unit that handle multiple execution units MISD computer manipulates the same data stream with different instruction at a time. It involves multiple control unit, multiple processing units and single execution unit. This concept is for theoretical interest and is not feasible practically. Hence attention has not been paid to implement this architecture. Multiple control units receive multiple instructions from centralized memory. Each instruction from centralized unit is passed to its corresponding processing unit. Then all these instructions operate on the same data provided by centralised common memory. MIMD computer involves the execution of multiple instruction on multiple data stream. Hence it involves multiple processor. Array processor is a processor that performs computations on large array of data underpipeline. The term is used to refer to two different types of processors. An attached array processor is n auxiliary processor attached to a general purpose. An SIMD array processor is a processor that has a single instruction multiple data organisation. It manipulates vector instructions by means of multiple functional units responding to a common instruction. An attached array processor is designed as peripheral for a conventional host computer, and its purpose is to enhance the performance of the computer by providing vector processing for complex scientific applications. It achieves high performance by means of parallel processing with multiple functional units. It includes an arithmetic unit containing one or more pipelined. The array processor can be programmed by the user to accommodate a variety of complex arithmetic problems. When the different tasks are executed by different hardware unit is called pipeline. These types of computer provide the high level of parallelism by having multiple processors. Q. Write short note on Hazards of pipelining. Ans. Pipelining is a techniques of decomposing a sequential process into suboperations, with each subprocess being executed in special dedicated segment that operates Concurrently with all other segments. Pipeline can be visualized as a collection of processing segments through which binary information flows. Each segment performs partial processing. The result obtained from computation in each segment is transferred to next segment in pipeline. It implies a flow of information to an assembly line. The Simplest way of viewing the pipeline structure is that each segment consists of an input register followed by a Combination circuit. The register holds the data and the combinations circuit performs the sub operations in the particular segment. The output of Combination CK is applied to input register of the next segment. A clock is applied to all registers after enough time has elapsed to perform all segment activity. Q. Explain description. instruction set of SPARC with Ans. SPARC machine use instruction that thirty-two bits long. The machine has an instruction type for algebric instruction, for branch instruction, and for jump instruction (f-format and format & instructions). The layout of SPARC Instructions (branch) instruction is Format Two The SPARC Call Instruction, used to transfer control to anywhere in 32 bit address As usual, the cond operand transfers constant. the first two bits specify the instruction type, is the Branch condition and the op2 is the to compare against. It met the machine control to location specified by the 22 bit Non-branch format two instruction is Format three: (Algebric Instructions) These instruction are the most common instructions. They are either algebric instruction to load/store instruction. Q. What are reasons of pipeline conflicts pipelined processor ? How are they resolved? in Ans. There are following reasons which create the conflicts in pipelined processor and way by which it is resolved: 1. Resource conflicts : It caused by access to memory by two segments at the same time. Most of these conflicts can be resolved by using separate instruction and data memories. 2. Data dependency conflict : It arise when an instruction depends on the result of a previous instruction, but this result is not yet available. 3. Branch difficulties: It arise from branch and other instructions that change the value of PC. A difficulty that may cause a degradation of performance in an instruction in pipeline is due to possible collision of data or address. A collision occurs when an instruction cannot proceed because previous instructions did not complete certain operations. A data depending occurs when an instruction needs data that are not yet available. For example, an instruction in the Fetch operand segment may need to fetch an operand that is being generated at the same time by the previous instruction in segment EX (Execute). Therefore, the second instruction must wait for data to become available by the first instruction. Similarly, an address dependency needed by address mode is not available. For example, an instruction with register indirect mode cannot proceed to fetch the operand if the previous instruction is loading the address into the register. Therefore, the operand access to memory must be delayed until the required address is available. Pipelined computers deal with such conflicts between data dependencies in a variety of ways. The most straight forward method is to insert Hardware inter locks. An interlock is a circuit that detects instructions whose source operands are destinations of instructions farther up in pipeline. This approach maintains the program sequences by using hardware to insert the required delays. Another technique called operand forwarding uses special hardware to detect a conflict and then avoid it by routing the data through special paths between pipeline segments. for example, instead of transforming an ALU result into a destination register, hardware checks the destination operand and if it is needed as a source in the next instruction, it passes the result directly into ALU input, by passing the register file. This method requires additional hardware paths through multiplexers as well as the circuit that detects the conflict. A procedure employed in some computers is to give the responsibility for solving data conflicts problems to the compiler that translates the high-level programming language into a machine language program. Q. What do you mean by software and Hardware interrupts ? How these are used in microprocessor. Ans. Hardware and software interrupts : Interrupts caused by I/O devices are called Hardware interrupt. The normal operation of a micro processor can also be interrupted by abnormal internal conditions or special instruction. Such an interrupt is called a software interrupt. RST is instruction of processor are used for software interrupt. When RST n instruction is inserted in a program, the program is executed upto the point where RST n has been inserted. This is used in debugging of a program. The internal abnormal or unusual conditions which prevent processing sequence of a microprocessor are also called exceptions. For example, divide by zero will cause an exception. Intel literature do not use the form exception. Where Motorola literature use the term exception. Intel includes exception in software interrupt when several I/O devices are connected to INR interrupt line, an external Hardware is used to interface I/O devices. The external Hardware circuits generate RSTn codes to implement the multiple interrupt scheme. P.ST 7.5, RST 6.5 and RST 5.5 are maskable interrupts. These interrupts are enabled by software using instructions El and SIM (Set interrupt mask). The excretion of instruction SIM enables/disables interrupts according to hit pattern of accemable. Bit — 0 to 2 rest/ set the mask bits of interrupt mask for RST 5.5, 6.7 and 7.5. Bit 0 for RST 5.5 mask, bit I for RSI 6.5 mask and bit 2 for RST 7.5 mask. If a bit is set of the corresponding interrupt is masked off (disable). If it is set to 0, corresponding interrupt is enabled. Bit 3 is set to 1 to make bits 0 - 2 effective. Bit 4 is an additional control for RSI 7.5. If it is set to I the flip- flop for RST 7.5 is reset. These RST 7.5 is disabled regardless of whether bit 2 for RST 7.5 is 0 or 1. Q. What do you mean by memory hierarchy ? Briefly discuss. Ans. Memory is technically any form of electronic storage. Personal computer system have a hierarchical memory structure consisting of auxiliary memory (disks), main memory (DRAM) and cache memory (SRAM). A design objective of computer system architects is to have the memory hierarchy work as through it were entirely comprised of the fastest memory type in the system. Q. What is Cache memory? Ans. Cache memory: Active portion of program and data are stored in a fast small memory, the average memory access time can be reduced, thus reducing the execution time of the program. Such a fast small memory is referred to as cache memory. It is placed between the CPU and main memory as shown in figure. Q. What do you mean by interleaved memory? Ans. The memory is partitioned into a number of modules connected to a common memory address and data buses. A primary module is a memory array together with its own addressed data registers. Figure shows a memory unit with four modules. Q. How many memory chips of4128x8) are needed to provide memory capacity of 40 x 16. Ans. Memory capacity is 4096 x 16 Each chip is 128 8 No. of chips which is 128 x 8 of 4096 x 16 memory capacity Q. Explain about main memory. Ans. RAM is used as main memory or primary memory in the computer. This memory is mainly used by CPU so it is formed as primary memory RAM is also referred as the primary memory of computer. RAM is volatile memory because its contents erased up after the electrical power is switched off. ROM also come under category of primary memory. ROM is non volatile memory. Its contents will be retained even after electrical power is switched off. ROM is read only memory and RAM is read-write memory. Primary memory is the high speed memory. It can be accessed immediately and randomly. Q. What is meant by DMA? Ans. DMA : The transfer of data between a fast storage device such as magnetic disk and memory is limited by speed of CPU. Removing the CPU from the path and letting the peripheral device manager the memory buses directly would improve speed of transfer. This transfer technique is called Direct my Access (DMA) During DMA transfer, the CPU is idle. A DMA controller takes over the buses to manage the transfer between I/O device and memory Q. Write about DMA transfer. Ans. The DMA controller is among the other components in a computer system. The CPU communicates with the DMA through the address and data buses with any interface unit. The DMA has its own address, which activates with Data selection and One the DMA receives the start control command, it can start the transfer between the peripheral device and CPU. Q. Differentiate among associate mapping. direct mapping and Ans. Direct mapping : The direct mapped cache is the simplest form of cache and easiest to check for a hit. There is only one possible place that any memory location can be cached, there is nothing to search. The line either contain the memory information it is looking for or it does not. Associate mapping : Associate cache is content addressable memory. The cache memory does not have its address. Instead this memory is being accessed using its contents. Each line of cache memory will accommodate the address and the contents of the address from the main memory. Always the block of data is being transferred to cache memory instead of transferring the contents of single memory location from main Q. Define the terms: Seek time, Rotational Delay, Access time. Ans .Seek time : Seek time is a time in which the drive can position its read/write ads over any particular data track. Seek time varies for different accesses in tie disk. It is preferred to measure as an average seek time. Seek time is always measured in milliseconds (ms). Rotational Delay: All drives 1bve rotational delay. The time that elapses between the moment when the read/we heal\settles over the desired data track and the moment when the first byte of required data appears under the head. Access time: Access time is simply the sum of the seek time and rotational latency time. Q. What do you mean by DMA channel? Ans. DMA channel: DMA channel is issued to transfer data between main memory and peripheral device in order to perform the transfer of data. The DMA controller access rs address and data buses. DMA with help of schematic diagram of controller ontile needs the dual circuits of and e to communicate with CPU and I/O device. In addition, it nee s an address register; a word count register, and a set of, es The address register and address lines are used rec communication with memory to word count register specifies the no. of word that - must be trEia transfer may be done directly between the device and memory . Figure 2 shows the block diagram of typical DMA controller. The unit communicates with CPU via the data bus and control lines. Q. RAM chip 4096 x 8 bits has tio enable lines. How many pins are needed for the iegrated circuits package? Draw a block diagram and label all input and outputs of the RAM. What is main feature of random access memory? Ans. (a) Total RAM capacity of 4096. Moreover the size of each RAM chip in 1024 x 8, that means total number of RAM chips required. 4O96 1024 That means total 4RAM chips are required of 1024 x 8 RAM. No. of address lines required to map each RAM chip of size 1024 x 8 is calculated as specified ahead. 2 = 1024; 2 = n = 10 that means 10 bit address is required to map each RAM chip of size 1024 x 8. 8-bit data bus is required for RAM because number after multiplication is 8 in RAM chip of size 1024 x 8. 10 bit address bus is required to map 1024 x 8RAM. The 11th and bit is used to select one of four RAM chips. Here we will take 12 bit of address bus because of 11th and 12th bit will select one of the four RAM chip as shown in memory address in Diagram. N0Q. The RAM 1C as described above is used in a microprocessor system, having 16b address line and 8 bit data line. It’s enable — 1 input is active when A15 and A14 bjjóre 0 and 1 and enable -2 input is active when A13, A12 bits are ‘X’ and ‘0’. Q. What shall be the range of addresses that is being used by the RAM. Ans. The RAM chip is better suited for communication with the CPU if it has one or more control inputs that selects the chip only when needed. Another there is bidirectional data bus that allows the transfer of data either from memory to CPU during a read operation, or from CPU to memory during a write operation. A bidirectional bus can be three-state buffer. A three-stats buffer output can be placed in one of three possible states a signal equivalent to logic , a signal equivalent to logic 0, or a high impedance state. The logic 1 and 0) are normal digital signals. The high impedance state behaves like an open circuit which means that the output doesnot carry a signal and has no logic significance. The block diagram of a RAM chip is shows in figure. The capacity of memory is 216 work of 16 bit per word. This requires a 16-bit address and 8-bit bidirectional data bus. It has A13 and A12 bits which 1 and 0, 0 and 0 then it is active to accept two input through chip select CSI and CS2. If A15, A14 bits are 0 and I then one input is acceptable it is active i.e. it is from CS1 or CS2 (Chip selections). General Functional table Q. Design a specifications. CPU that meets the following Ans .can access 64 words of memory, each word being 8-bit long. The CPU does this outputting a 6-bit address on its output pins A [5 0] and reading in the 8-bit value from memory on inputs D [7,...O]. It has one 8-bit accumulator, s-bit address register, 6-bit program counter, 2-bit instruction register, 8 bit data register. The CPU must realise the following instruction set: AC is Accumulator MUX is Multiplexer Here instruction register has two bits combination i.e. Instruction Code Instruction Operation 00 ADD AC - AC + M[A] 01 AND AC - AC A M[A] 10 JMP AC - M[A] 11 INC AC - AC + I Q. What are the advantages you got with virtual memory? Ans permit the user to construct program as though a large memory space were available, equal to totality auxiliary memory. Each address that is referenced by CPU goes through an address mapping from so called virtual address to physical address main memory. There are following advantages we got with virtual memory: 1. Virtual memory helps in improving the processor utilization. 2. Memory allocation is also an important consideration in computer programming due to high cost of main memory. 3. The function of the memory management unit is therefore to translate virtual address to the physical address. 4. Virtual memory enables a program to execute on a computer with less main memory when it needs. 5.Virtual memory is generally implemented by demand paging concept In demand paging, pages are only loaded to main memory when they are required 6.Virtual memory that gives illusion to user that they have main memory equal to capacity of secondary stages media. The virtual memory is concept of implementation which is transferring the data from secondary stage media to main memory as and when necessary. The data replaced from main memory is written back to secondary storage according to predetermined replacement algorithm. If the data swajd is designated a fixed size. This concept is called paging. If the data is in the main viiI1ze subroutines or matrices, it is called segmentation. Some operating systems combine segmentation and paging. Q. Write about DMA transfer. Ans .the CPU communicates with DMA through the address and data buses as with a interface unit. The DMA has its own address, which activates the DS and RS line. CPU initializes the DMA through the data bus. Once the DMA receives the start control command, it can start the transfer between peripheral device and the memory. When the peripheral device sends a DMA request, the DMA controller activates the BR line, informing the CPU to relinquish the buses. The CPU responds with its BC line, informing the DMA that its buses are disabled. The DMA then puts the current value of its address register with address bqs, initiates the RD WR signal, and sends a DMA acknowledge to the peripheral device. RD and WR lines in DMA controller are bidirectional. The direction of transfer depends on the status of BC line. When BG = 0, the RD and WR are input lines allowing CPU to communicate with the internal DMA register when BC =1, the RD and WR are output lines from the DMA controller to random-access memory to specify the read or write operation for the data. When the peripheral device receives a DMA acknowledge, it puts a word in the data bus (for write) or receives a word from the data bus (for read). Thus the DMA controls the read or write operations and supplies. The address for the memory through the data bus for direct transfer between two units while CPU is momentarily disabled. DMA transfer is very useful in many applications . It is used for fast transfer of information between magnetic disks and memory. It is also useful for updating the display in an interactive terminal. The contents of memory is transferred to the screen periodically by means of DMA transfer. Q. What is memory organization ? Explain various memories ? Ans .The memory unit is an essential component in any digital computer since it is needed for storing programs and data A very small computer with a limited application may be able to fulfill its intended task without the need of additional storage capacity, Most general purpose computer is run more efficiently if it is equipped with additional storage beyond the capacity of main memory. There is just not enough in one memory unit to accommodate all the programs used in typical compui Mbst computeiusers accumulate and continue to accumulate large amounts of data processing software. There, it is more economical to use low cost storage devices to serve as a backup for storing. The information that is not currently used by CPU. The unit that communicates directly with CPU is called the main memory Devices that provide backup memory The most common auxiliary memory device used auxiliary system are magnetic disks and tapes. They are used for storing system programs, large data files, and other backup information. Only proposed data currently needed by the processor reside in main memory All other information is stored in auxiliary memory and transferred to main memory when needed. There are following types of Memories: 1. Main memory * RAM (Random - Access Memory) * ROM (Read only Memory) 2. Auxiliary Memory * Magnetic Disks * Magnetic tapes etc. 1. Main Memory: The main memory is central storage unit in computer system. It is used to store programs and data during computer operation. The technology for main memory is based on semi conductor integrated circuit. RAM (Random Access Memory): Integrated circuit RAM chips are available in two possible operating modes, static and dynamic. The static RAM consists of internal flip flops that store the binary information. The dynamic RAM stores binary information in form of electric charges that are applied to capacitors. ROM: Most of the main memory in general purpose computer is made up of RAM integrated chips, but a portion of the memory may be constructed with ROM chips. Rom is also random access. It is used for string programs that are permanently in computer and for tables of constants that do not change in value once the production of computer is completed. 2. Auxiliary Memory : The most common auxiliary memory devices used in computer systems are magnetic disks and magnetic ‘tapes. Other components used, but not as frequently, are magnetic drums, magnetic bubble memory, and optical disks. Auxiliary memory devices must have knowledge of magnetic, electronics and electro mechanical systems There are following auxiliary memories. Magnetic Disk: A magnetic .Disk is a circular plate constructed of metal or plastic coated with magnetized material. Both sides of the disk are used and several disks may be stacked on one spindle with read/write heads available on each surface. Bits are stored in magnetised surface in spots along concentric circles called tracks. Tracks are commonly divided into sections called sectors. Disk that are permanently attached and cannot removed by occasional user are called Hard disk. A disk drive with removable disks are called a floppy disks. Magnetic tapes: A magnetic tape transport consists of electric, mechanical and electronic components to provide the parts and control mechanism for a magnetic tape unit. The tape itself is a strip of plastic coated with a magnetic recording medium. Bits are recorded as magnetic spots on tape along several tracks. Seven or Nine bits are recorded to form a character together with a parity bit R/W heads are mounted one in each track so that data can be recorded and read as a sequence of characters. Q. Compare interrupt I/O with DMA T/O? Ans. There is following given interrupt I/O with DMA I/O. comparison between Q.What do you mean by initialization of DMA controller ? How DMA Controller works? Explain with suitable block diagram ? Ans. The DMA controller needs the usual circuits of an interface to communicate With CPU and I/O device. In addition, it needs an address register, a word count register, and a set of address line. The address register and address line are used for direct communication with the memory. The word count register specifies the number of words that must be transferred. The data transfer may be done directly between the device an memory under control of DMA, Figure 2 shows the block diagram of a typical DIA controller. The unit communicate with CPU via data bus and control lines. The registers in DMA are selected by CPU through address bus by enabling PS (DMA select) and RS (register select) inputs. The RD (read) and WR (write) inputs are bidirectional When the BG (Bus grant) Input is 0, The CPU is in communicate with DMA registers through the data bus to read from or write to DMA registers. When BC 1, the CPU has the buses and DMA can communicate directly with the memory by specifying a address in the address bus and the activating the RD or WR control. The DMA communicate with the external peripheral through the request and acknowledge lines by using handshaking procedure. The DMA controller has three register : an address register, a word count register, and control register. The address register contains an address to specify the desired location in memory. The address bits go through bus buffers into the address bus. The address register is incremented after each word that is transferred to memory. The word count register holds the number of words to be transferred. The register is decremented by one after each word transfer and internally tested for zero. The control register specifies the mode of transfer. All register in DMA appear to CPU as I/O interface register. Thus the CPU can read from or write into DMA register under program control via the data bus. transfer data be memory a per unit transferred Block diagram of DMA controller. The initialization process is essentially a program consisting pf I/O instructions that include the address for selecting particular DMA registers. The CPU’ initializes the DMA by sending the following information through data bus: 1. The starting address of the memory lock here data liable (for read) or when the data are stored (for write). 2. The word cont, which is the number of words in memory block. 3. Control to specifically the modes of transfer such as reader Write. 4. A control to start the DMA transfer. the starting address is stored in the address register. the word count is stored in the word register the control information in the control register. When DMA is initialized, the CPU stops communicating with DMA unless it receives an interrupt signal or if it wants to check how many words have been transferred. Q. 22. When a DMA module takes control of bus and while it retain control of bus, what does the processor do. Ans. The CPU communicates with the DMA through the address and data buses as with any interface unit. The DMA has its own address, which activates the 1)5 and RS lines. The CPU initializes the DMA through the data bus. Once the DMA receives the start control command, it can start the transfer between peripheral device and the memory. When the peripheral device sends a DMA request, the DMA controller activates the BR line, informing the CPU responds with its HG line, informing the DMA that its buses are disabled. The DMA then puts the current value of its address register into the address bus, initiate the RD or WR signal and sends a DMA acknowledge to the peripheral device. Note that RD and WR lines in DMA controller are bidirectional. The direction of transfer depends on the status of BG line. When BG 0, the RD and WR are input lines allowing the CPU to communicate with internal DMA registers. When BC = 1, the RD and WR are output lines from DMA controller to the random access memory to specify the read or write operation for the data. When the peripheral device receives a DMA acknowledge, it puts a word in the data bus (for write) or receives a word from the data bus (for read). Thus the DMA controls the read or write operations and supplies the address for the memory. The peripheral unit can then communicate with memory through the data bus for direct transfer between the two units while the CPU is momentarily disabled. For each word that is transferred, the DMA increments its address register and decrements its word count register. If the word count does not reach zero, the DMA checks the request line coming from peripheral. For a high speed device, the line will be active as soon as the previous transfer is completed. A second transfer is then initiated, and the process continues until the entire block is transferred. If the peripheral speed is slower, the DMA request line may come somewhat late. In this case the DMA disables the bus request line so that the CPU can continue to execute its program, when the peripheral requests a transfer, DMA requests the buses again. If the word count register reaches zero, the DMA stops any further transfer and removes its bus request. It also informs the CPU of the termination by means of interrupts when the CPU responds to interrupts, it reads the content of word count register. The zero value of this register indicates that all the words were transferred successfully. The CPU can read this register at any time to check the number of words already transferred. A DMA controller may have more than one channel. In this case, each channel has a request and acknowledge pair of control signals which are connected to separate peripheral devices. Each channel also has its own address register and word count register within the DMA controller. A priority among the channels may be established so that channels with high priority are serviced before channels with lower priority. DMA transfer is very useful in many application. It is used for fast transfer of information between magnetic disks and memory. It is also useful for updating the display in an interactive terminal. The contents of memory can be transferred to the screen by means of DMA transfer. Q. 23. (a) How many 128 x 8 RAM chips are needed to provide a memory capacity of 2048 bytes? (b) How many lines of the address bus must be used to access 2048 bytes of memory ? How many these lines will be common to all chips? (c) How many lines must be decoded for chip select ? Specify the size of recorder. 2048 Q. 24. A computer uses RAM chips of 1024 x 1 capacity. (a) How many chips are needed, and how should there address lines be connected to provide a memory capacity of 1024 bytes? (b) How many chips are needed to provide a memory capacity of 16K bytes? Explain in words how the chips are to be connected to the address bus ? Specify the size of the decoders. 1024 . Q. 26. An 8-bit computer has a 16-bit address bus. The first 15 lines of address are used to select a bank of 32K bytes of memory. The higher order bit of address is used to select a register which receives the contents of the data bus ? Explain how this configuration can be used to extend the memory capacity of system to eight banks of 32 K bytes each, for a total of 256 bytes of memory. Ans. The processor selects the external register with an address 8000 hexadecimal. Each bank of 32K bytes are selected by address 0000—7 FFF. The processor loads an 8-bit number into the register with a single I and seven 0’s. Each output of register selects one of the 8 banks of 32 bytes through 2-chip select input. A memory bank can be changed by changing in number in the register. Q. 27. A Hard disk with 5 platters has 2048 tracks/ platter, 1024 sector/track (fixed number of sector per track) and 512 byte sectors. What is its total capacity? Ans. 512 bytes x 1024 sectors 0.5 MB/track. Multiplying by 2048 tracks/platter gives 1GB/plat platter, or 5GB capacity in the driver. (in the problem, we use) the standard computer architecture definition of MB 220 bytes and GB 230 bytes, many hard disk manufactures use MB = 1,000,000 bytes and GB = 1,000,000,000 bytes. These definitions are close, but not equivalent. Q. 28. A manufactures wishes to design a hard disk with a capacity of 30 GB or more (using the standard definition of 1GB = 230 bytes). If the technology used to manufacture the disks allows 1024-bytes sectors,.. 2048 sector/track, and 40% tracks/ platter, how many platter are required? Ans. Multiplying bytes per sector times sectors per tracks per platter gives a capacity of 8 GB (8 x 230) per platter. Therefore, 4 platter will he required to give a total capacity of 30GB. Q. 29. If a disk spins at 10,000 rpm vhat is the average rational latency time of a request? If a given track on the disk has 1024 sectors, what is the transfer time for a sector? Ans. At 10,000 r/min, it takes 6ms for a complete rotation of the disk. On average, the read/write head will have to wait for half rotation before the needed sector reaches it, SC) the average rotational latency will be 3ms. Since there are 1024 sectors on the track, the transfer time will he equal to the rotation time of the disk divided by 1024, or approximately 6 microseconds. Q. 30. In a cache with 64-byte cache lines how may bits are used to determine which byte within a cache line an address points to ? Ans. The 26 = 64, so the low 6 hits of address determine an address’s byte within a cache line. Q. 33 For a cache with a capacity of 32 KB, How many lines does the cache hold for line lengths of 32, 64 or 128 bytes? Ans. The number of lines in cache is simply the capacity divided by the line length, so the cache has 1024 lines with 32-byte lines, 512 lines with 64-byte lines, and 256 lines with 128 byte lines. Q. 34. If a cache has a capacity of 16KB and a line length of 128 bytes, how many sets does the cache have if it is 2-way, 4-way, or 8-way set associative? Ans. With 128-byte lines, the cache contains a total of 128 lines. The number of sets in the cache is the number of lines divided by the associativity so cache has 64 sets if it is 2-way set association, 32 sets if 4-way set associative, and 16 set if 8-way set-associative. Q. 35. If a cache memory has a hit rate of 75 percent, memory request take l2ns to complete if they hit in the cache and memory request that miss in the cache take 100 ns to complete, what is the average access time of cache? Ans. Using the formula, The average access time =(THit X H1t) + (TmissX miss) The average access time is (12 ns x 0.75) + (100 ns x 0.25) = 34 ns. Q. 36. In a two-level memory hierarchy, if the cache has an access time of ns and main memory has an access time of 60ns, what is the hit rate in cache required to give an average access time of 10ns? Ans. Using the formula, the average access time = (THit X Hit) + (Tmiss x miss) The average access time 10ns = (8ns x hit rate) + 60 ns x(1 — (hit rate)), (The hit and miss rates at a given level should sum to 100 percent). Solving for hit rate, we get required hit rate of 96.2%. Q. 37. A two-level memory system has an average access time of l2ns. The top level (cache memory) of memory system has a hit rate of 90 percent and an access time of 5ns. What is the access time of lower level (main memory) of the memory system. Ans. Using the formula, the average access time = (“THIT x PHIT) + miss) The average access time = l2 (5 x 0.9) + (Tmiss x 0.1). Solving for Tmiss, we get Tmiss 75 ns, Which is the access time of main memory. Q. In direct-mapped cache with a capacity of 16KB and a line length of 32 bytes, how many bits are used to determine the byte that a memory operation references within a cache line, and how many bits are used to select the line in the cache that may contain the data? Ans. 2 = 32, so 5 bits are required to determine which byte within a cache line is being referenced with 32-byte lines, there are 512 lines in 16KB cache, so, 9 bits are required to select the line that may contains the address (2 = 512). Q. The logical address space in a computer system consists of 128 segments. 'Each segment can have up to 32 pages of 4K words in each physical memory consists of 4K blocks of 4K words in each. Formulate the logical and physical address formats. Ans. Logical address: Q. A memory system contains a cache, a main memory and a virtual memory. The access time of the cache is 5ns, and it has an 80 percent hit rate. The access time of the main memory is 100 ns, and it has a 99.5 percent hit rate. The access time of the virtual memory is 10 ms. What is average access time of the hierarchy. Ans. To solve this sort of problem, we start at the bottom of the hierarchy and work up. Since the hit rate of virtual memory is 100 percent, we can compute the average access time for requests that reach the main memory as (l00n s x 0.995) + (10 ns x 0.005) = 50,099.5 ns. Give this, the average access time for requests that reach the cache (which is all request) is (5ns x 0.80) + (50,099.5 ns x 0.20) = 10,024 ns. Q. Why does increasing the capacity of cache tend to increase its hit rate? Ans. Increasing the capacity Of cache allows more data to be stored in cache. If a program references more data than the capacity of a cache, increasing the cache’s capacity will increase the function of a program’s data that can be kept in the cache. This will usually increase the bit rate of the cache. If the program references less data than capacity of a cache, increasing the capacity of the cache generally does not affect the hit rate unless this change causes two or more lines that conflicted for space in the cache to not conflict since the program does not need the extra space. Q. Extend the memory system of 4096 bytes to 128 x 8 bytes of RAM and 512 x 8 bytes of ROM. List the memory address map and indicate what size decoder are needed if CPU address bus lines are 16 4096 Ans. Number RAM chips = 32 Therefore, 5 x 32 decoder are needed to select each of 32 chips. Also 128 = 2, First 7 lines are used as a address lines for a selected RAM 4096 Number of ROM chips = 8. Therefore, 3 x 8 decoders are needed to select each of 8 ROM chips. Also 512 = 2, First 9 lines are used as a address line for a selected ROM. Since, 4096 = 212, therefore, There are 12 common address lines and I line to select between RAM and ROM. The memory address map is tabulated below Q. A computer employ RAM chips f 256 x 8 and ROM chips of 1024 x 8. The computer system needs 2k byte of RAM, 4K. bytes of ROM and four interface units, each with four register. A memory mapped 1/0 configuration is used. The two highest order bits of the address assigned 00 for RAM, 01 for ROM, and 10 for interface registers. (a) How many RAM and ROM chips are rteded? (b) Draw a memory-address map for the system. Q .what is an I/O processor ? Briefly discuss. Ans. I/O processor is designed to handle I/O processes of device or the computer. This processor is separated from the main processor (CPU). It controls input/output operation only. The computer having I/O processor relieves CPU from input output burden. I/O processor cannot work independently and is controlled by the CPU. If I/O processors have been removed and given its job to a general purpose CPU. It is specialized devices whose purpose is to take load of I/O activity from the main CPU. Q . Write major requirement for I/O module. Ans. I/O module consists of following main components as its requirement. (a)-Connection to the system bus. (b) Interface module. (c) Data Buffer. (d) Control logic gates. (e) Status/control register. All of these are basic requirement of I/O module. Q. Write characteristics of I/O channels. Ans. The characteristics of I/O channels are given below: 1.I/O channel is one of data transfer technique which is adopted by peripheral. 2. I/O channel has the ability to execute I/O instruction. These instructions are stored in the main memory and are executed by a special purpose processor of I/O channel. 3. Multiplexer I/O channel handles I/O with multiple devices at the same time. 4. I/O channel is the concept where the processor is used as 1/0 module with its local memory. Q. What is channel? Ans. Channel: The channel is a way where the data is transferred. It is also a transfer technique which is adopted by various devices. It is path which is considered as interface between various device. Here I/O channel which is used with peripherals. There is no. of instruction stored in main memory and are executed by special purpose processor of the I/O channel. There is various types of channels i.e. multiplexer channel, selector channel and Block multiplexer channel etc. The data is transfers between devices and memory. Q. (a) Explain about I/O modes. Ans. The CPU executes the I/O instructions and may accept the data temporally, but the ultimate source or destination is the memory unit. Data transfer between the control computer and I/O devices which handled in variety of I/O modes. Some I/O modes use the CPU as an intermediate path; others transfer the data directly to and from the memory unit data transfer to and from peripherals may be handled in various possible I/O modes i.e. (a) Programmed I/O mode (b) Interrupt initiated I/O mode (c) Direct Memory Access (DMA). Q.(b) What is basic function of interrupt controller ? Ans. Data transfer between CPU and an I/O device is initiated by CPU. However, the CPU start the transfer unless the device is ready to communicate with CPU. The CPU responds to the interrupt request by storing the return address from PC into a memory stack and then the program branches to a service routine that processes the required transfer. Some processors also push the current PSW (program status word) auto the stack and load a new PSW for the serving routine, it neglect PSW here in order not to complicate the discussion of I/O interrupts. A priority over the various sources to determine which condition is to be serviced first when two or more requests arrive simultaneously. The system may also determine which conditions are permitted to interrupt the computer while another interrupt is being serviced. Higher-priority interrupts levels are assigned to requests which if delayed or interrupted, could have serious consequences. Devices with high speed transfers such as magnetic disks are given high priority, and slow devices such as keyboard receive low priority. When two devices interrupt the computer at the same time,. the computer services the device, with higher priority first. When a device interrupt occurs, basically it is checked through Daisy chaining priority method into determine which device issued the interrupt. Q. Write and explain all classes of interrupts. Ans. There are two main classes of interrupts explained below: 1. Maskable interrupts. 2. Non-maskable interrupts. 1. Maskable interrupts : The commonly used interrupts by number are called maskable interrupts The processor can ask o temporarily ignore such interrupts These interrupts are temporarily 1gnred such that processor can finish the task under execution. The processor inhibits (block) these types of interrupts by use of special interrupt mask bit. This mask bit is part of the condition code register or a special interrupt request input, it is ignored else processor services the interrupts when processor is free, processor will serve these types of interrupts. 2. Non-Maskable Interrupts (NMI) Some interrupts cannot be masked out or ignored by the processor. These are referred to as non-maskable interrupts. These are associated with high priority tasks that cannot be ignored. Example system bus faults. The computer has a non-maskable interrupts (NMI) that can be used for serious conditions that demand the processor’s attentions immediately. The NMI cannot ignored by the system unless it is shut off specifically. In general most processors support the nonmaskable interrupt (NMI). This interrupt has absolute priority. When it occurs the processor will finish the current memory cycle and then branch to a special routine written to handle the interrupt request. When a NMI signal is received the processor immediately stops whenever it as doing and attends to it. That can lead to problem if these type of interrupts are used improperly. The NMI signal is used only for critical problem situation like Hardware errors. Q.Explain processor. about 1/0 processor/information Ans. Input/Output processor/information processor: It is designed to handle input/ output processes of a device or the computer. This processor is separate from the main processor (CPU). I/O processor is similar to CPU but it controls input output operations only. The computer having I/O processor relieves CPU from Input/output operations only. CPU is the master processor of the computer and it instructs the I/O processor to handle the input output tasks. I/O processor cannot work independently and is controlled by the CPU. The I/O processor is composed of commercially available TTL logic circuits that generate the micro instructions necessary to implement the I/O instructions. The I/O processor is fully synchronous with the system clock and main processor. it receives starting control from the main processor (CPU) whenever an input output instruction is read from memory. The I/O processor makes use of system buses after taking the permission from the CPU. It can instruction the I/O processor 1/0 processor responds to CPU by placing a status word at prescribed location to be checked out by the CPU later on CPU informs the 1/0 processor to find out the 1/0 program and ask 1/0 processor to transfer the data. I/O processor can detect and correct the transmission errors. I/O processor can have its own I/O register. The I/O instruction require six to twelve microsecond to execute. There are I/O instructions for setting or clearing flip flops, testing the state of flip flops and moving data between registers in the main processor and the input! output register. I/O processor are specialized devices whose purpose is to take the load of I/O activity from the main CPU. The simplest I/O processor is DMA controller. Complex I/O processor are full computers dedicated to one task like NFS servers, X-terminals, terminal concentrators. Other I/O processor are like graphics accelerators, channels controller and network interfaces. Q.Explain various addressing modes in detail. Ans. The addressing mode specifies a rule for interpreting or modifying the address field of the instruction before the operand is actually referenced. Computers use addressing mode techniques for the purpose of accommodating one or both of the following provision: (a) To give programming versatility to the user by providing such facilities as pointers to memory, counter for ioop control, indexing of data, and program relocation. (b) To, reduce the number of bits in the addressing field of the instruction. There are following addressing modes given below: 1. Immediate Addressing mode : In this mode the operand is specified in the instruction itself. In other words, an immediate mode instruction has an operand field rather an address field. The operand field contain the actual operand to be used in conjunction with operations-specified in instruction. Immediate mode instructions are useful for initialising registers to a constant value. 2. Register mode: In this mode, the operands are in registers that reside within the CPU. The particular register is selected from register field in instruction. A kbit field can specify any one of 2k register. 3. Register indirect mode : In this mode the instruction specifies a register in the CPU whose contents give the address of the operand in memory. In other words, the selected register contains the address of operand rather than operand itself. Before using a register indirect mode instruction, the programmer must ensure that the memory address of the operand is placed in processor register with a previous instruction. A reference to the register is than equivalent to specifying a memory address. The advantage of a register indirect mode instruction is that the address field of the instruction uses fever bits to select a register than would have required to specify a memory address directly. 4. Auto increment or Auto decrement mode : This is similar to register indirect mode except the register is incremented or decremented after (or before) its value is used to access memory. When the address stored in register refer to a table of data in memory, it is necessary to increment or decrement the register after every access to the table. This can be achieved by using the increment to decrement instruction. However, because it is such a common requirement some computers incorporate a special mode that automatically increments or decrements the contents of register after data access. 5. Direct address mode: In this mode the effective address is equal to the address part of the instruction. The operand resides in memory and its address is given directly by the address field of instruction. In a branch type instruction the address field specifies the actual branch address. The effective address in these modes is obtained from the following computation: Effective address= address part of instruction + content of CPU register. 6. Relative address mode: In this mode, the content of program counter is added of address part of the instruction in order to obtain the effective address. The address part of instruction is usually a signed number (in 2’s complement representation) which can be either positive or negative. When this number is added to the content of program counter, the result produces an effective address whose position in memory is relative to the address of the next instruction. 7. Indexed addressing mode: In this mode, the content of an index register is added to the address part of the instruction to obtain the effective address. The index register is special CPU register that contain an index value. The address field of instruction defines the beginning address of a data array in memory. Each operand in array is stored in memory relative to the beginning address. The distance between the beginning address and the address of the operand is the index value stored in the index register. Any operand in the arrays can be accessed with the same instruction provided that the index register contains the correct index value. The index register can be incremented to facilitate access to consecutive operands. 8. Base register addressing mode : In this mode, the content of a base register is added to address part of instruction to obtain the effective address. This is sisimilar to the indexed addressing mode except that the register is now called a base register instead of an index register. Q. What is the difference between isolated mapped VO and memory mapped input output. What are the advantages and disadvantages of each? Ans. Isolated I/O : In isolated mapped I/O transfer, there will be common address and data bus for main memory and I/O devices. The distinction memory transfer i l7transfer is made through control lines. There will be separate control signals for main memory and I/O device. Those signals are memory read, memory write, I/O read and I/O write. This is an isolated I/O method of communication using a common bus. When CPU fetches and decodes the operation code of input or output instruction, the address associated with instruction is placed on address bus. If that address is meant for I/O devices then 1/0 read or I/O write control signal will he enabled depending upon whether we want to read or write the data from I/O devices. If that address is meant for main memory then memory read or memory write signals will be enabled depending upon whether we want to read or write the data to main memory. Memory Mapped I/O: In memory-mapped I/O, certain address locations are not used by memory and I/O devices use these address. Example : It address from 0 to 14 are not used by main memory. Then these addresses can be assigned as the address of I/O devices. That means with above example we can connect with 15 I/O devices to system having addresses from 0 to 14. So we an have single set of address, data and control buses. It the address on address bus belongs to main memory. This will reduce the available address space for main memory but as most modern system are having large main memory so that is not normally problem. Memory mapped I/O treats I/O parts as memory locations programmer must ensure that a memory-mapped address used by I/O device is used as a regular memory address. There are following main point of difference between isolated mapped I/O and memory mapped I/O. The Advantage is that the load and store instructions used for reading and writing from memory can be used to input and output data from I/O registers. In a typical computer, there are more memory reference instructions than I/O instructions with memory-mapped I/O all instruction that refer to memory are also available for I/O. Q. When a device interrupt occurs, how does the processor determine which device issued the interrupt Ans. Data transfer between CPU and an I/O device is initiated by CPU. However, the CPU cannot start the transfer unless the device is ready to communicate with CPU. The CPU responds to the interrupt request by storing the return address on PC into a memory stack and then the program branches to a service routine that processes the required transfer. Some processors also push the current PSW (program status word) auto the stack and load a new PSW for the serving routine, it neglect PSW here in order not to complicate the discussion of I/O interrupts. A priority over the various sources to determine which condition is to be serviced first when two or more requests arrive simultaneously. The system may also determine which conditions are permitted to interrupt the computer while another interrupt is being serviced. Higher-priority interrupts levels are assigned to requests which if delayed or interrupted, could have serious consequences. Devices with high speed transfers such as magnetic disks are given high priority, and slow devices such as keyboard receive low priority. When two devices interrupt the computer at the same time,. the computer services the device, with higher priority first. When a device interrupt occurs, basically it is checked through Daisy chaining priority method into determine which device issued the interrupt. The daisy-chaining method of establishing priority consists of a serial connection of all devices that request an interrupt. The device with the highest is placed in first position, followed by lower-priority devices upto the device with the lowest priority which is placed last in chain. This method of connection between three devices and CPU is shown in figure. The interrupt request line is common to all devices and forms a wired logic connection. If any device has its interrupt signal in lowlevel state, the interrupt line goes to low level states and enables the interrupt input in CPU. When no interrupts are pending, interrupt line stays in the high level state and no interrupts are recognized by the CPU. This is equivalent to a negative logic OR operation. The CPU responds to an interrupt request by enabling the interrupt acknowledge line. This signal is received by device 1 at its P1 (priority in) input. The acknowledge signal passes on to next device through P0 (priority out) output only if device 1 is not requesting an interrupt. If devices has a pending interrupt, it blocks the acknowledge signal from next device by placing 0 in P0 output. If then proceeds to insert its own interrupt Vector Address (VAD) into the data bus for the CPU to use during the interrupt cycle. A device with 0 in its input generates a 0 in its P0 output to inform the next lower priority device that the acknowledge signal has been blocked. A device that is requesting an interrupt and has a 1 in its P1 input will intercept the acknowledge signal by placing 0 in its P0 output. If the device does not have pending interrupts, it transmits the acknowledge signal to the next device placing interrupts, a L in its P0 output ( Thus the device with P1 =1 and PC =0 is the one with the highest priority that is requesting an interrupt, and this device places its VAD on the data bus. The daisy chain arragement gives the highest priority to the device that receives the interrupts acknowledge signal from the CPU. The farther the device is form the first position, the lower to its priority. Figure shows the internal logic that must be included within each device when connected in the daisy chaining scheme. The device sets its RF flip-flop when its wants to interrupt the CPU. The Output of the R.F. flip-flop goes through an open-collector in verter, a circuit that provide the wired logic for the common interrupt line. If PT = 0, both PC and the enable line to VAD are equal to 0, irrespective of value of RF. If P1 = I and RF 0, then P0 = 1 and vector address is disabled. This condition passes the acknowledge signal to the next device through P0. The device is active when P1 = I and RF = 1. This condition places 0 in P0 and enables the vector address for the data bus. It is assumed that each device has its own distinct vector address. The RF flip-flop is reset after a sufficient delay to ensure that the CPU has received the vector address. Q. What is a multiprocess ? Explain the term SIMD. Ans. A multiprocessor system is having two or more processors. So, multiprocessor is which execute more than of one and two processes. The main feature multiprocessor system is to share main memory or other resources by all processors. SIMD : SIMD computer executes one instruction on multiple data items at a time. This is implemented in vector or array processing and multimedia extension (MMX) in Pentium. Here all processor receives the same instruction from control unit and implement it on different data items. There is single control unit that handle multiple execution units. Each processing unit has its own local memory module. Q. Compare SIMD and MIMD machine. Ans. SIMD : SIMD machine executes one instruction on multiple data items at a time. Here all processor receives the same instruction from control units and implement it on different data items. Here is single control unit that handle multiple execution unit. MIMD: MIMD Computer involves the execution of multiple instructions on multiple data stream. Hence this type of computer involves multiple processing. MIMD involves multiple control units, multiple processing units and multiple execution units. These types of computer provide the highest level of parallelism by having multiple processors. Q. Explain about parallel computers. Ans. Parallel computers provides parallelism in unprocessor or multiple processors can enhance the performance of computer. The concurrency in unprocessor or superscalar in terms of hardwares and software implementation can lead to faster execution of programs in computer. Parallel processing provides simultaneous data processing to increase the computational seed of computer. Q. Explain about MIMD machine. Ans. MIMD computer provides the execution of multiple instructions on multiple data stream. Hence the type of computer involves multiple processors. MIMD involves multiple central unit, multiple processing units and multiple execution units. These types of computer provide highest level, of parallelism by having multiple processors. Q. Explain computers about parallel and distribution Ans. Parallel Computer: Parallel computers require lots of processor-either in one computer or inside several linked machine going up to work on a single problem at one time. A typical desktop PC has one processor, a computer bit to handle parallel processing can have several hundred of processors. Specific areas where parallel processing is required in scientific industries, although its reach is slowly extending to the business world. The best candidates for parallel processing are projects that require many different computations. Single processor computers perform each computation sequentially. Using parallel processing, a computer can perform several computations simultaneously, drastically reducing the time it takes to complete a project. The medical community uses parallel processing super computers to analyses MRI images and study models of bus implant systems. Airline uses parallel processing to process customer information, to forecast demand and to decide what forces to charge. Distributed computer: In distributed systems, it should communicate with each other using some fixed set of rules (protocols). The methods for this communication include layered protocols, request/reply messing passing including (Remote procedure call) and group communication (i.e. multi-casting, broadcasting etc.). Another important thing that should be focused upon is how these processes should cooperate and synchronize with one another. This implies that methods to implement solutions for the critical section problem and resources allocation in a distributed systems must he known. It deals with inter-process co-operation and sychronization in distributed systems. It is clear that the methods to implement inter-process co-operation and. sychronization in distributed system is more complex and difficult to implement as compared to those in single CPU systems. Q. What is meant by hierarchical bus system for multiprocessing system? Ans. A system’s work load cannot be handled satisfactory by a single processor, one response is to apply multiple processors to the problem and this is known as multiprocessing environment. There are two types of multiprocessing system. 1. Symmetrical multiprocessing system 2. Asymmetric multiprocessing system. Hierarchical bus is also in this multiprocessing system. 1. Symmetrical multiprocessing system : In this, all of the processors are essentially identical and perform identical functions. Characteristics of such system can be specified as (a) Any processor can initiate an I/O operation can handle any external interrupt, and can run any processor in the system. (b) All of the processors are potentially available to handle whenever needs. to be done next: 2. Asymmetric multiprocessing system : Asymmetry implies imbalance, or some difference between processors. Thus, in asymmetric multiprocessing, different processors do different things. From design point of view, it is often implemented so that one processors job is to control the rest, or it is the supervisor of the others. Some advantages and disadvantages of this approach are: 1. In some situation, I/O operation application program processing may be faster because it does not have to contend with other operations or programs for access to a processor i.e. many processors may be available for a single job. 2. In other situations, I/O operation or application program processing can be slowed down because not all of the processors are available to handle peak loads. 3. In asymmetric multiprocessing, if the supervisor processor handling a specific work fails. The entire system will go down. Q. Explain about the multiprocessor? Ans. A multiprocessor system is having two or more processors. This type of system will have one master CPU to control all other processors. The other processor may be coprocessor or input-output processors. The main feature is to share main memory or other resources by all processor. The basic characteristics of multiprocessor system is as specified ahead. 1. This system must have more than one processor. All these processor must have nearly identical processing capabilities. 2. All these processor must have common shared memory. 3. Processors share all I/O devices or other resources. 4. The interaction among processors at program level must be defined precisely to have good and efficient design of hardware for multiprocessor system. 5. The system configuration can enhanced at required increments at any point of time. There are two types of multiprocessor i.e.rightly coupled and loosely coupled. Tightly coupled shares common memory and each processor is also have its own local memory. Loosely coupled multiprocessor is not having shared memory although each processor will have its own local memory. The processors used in this type of system are specialized to handle different tasks. This system increases the overall reliability of system. That means if one or two processor fails, their load is being shared by other processor. Present in system the different schemes used for interconnection of processors and memories are instead ahead 1. Common Bus. 2. Multiple Bus. 3. Gossbar switching. 4. Multistage interconnection network. 5. Multiport memory. 1. Common Bus : This scheme will provide single bus for interconnection of processors and memory. This scheme is most effective and very simple. The failure of bus system results in total system failure. Moreover the performance of overall system is being limited by data transfer rate of bus. 2. Multiple Bus Organisation : This system will provide two or more buses for interconnection of processor and memory. This scheme allows multiple data transfer simultaneously. This will increase reliability without increasing the cost too much. 3. Gossbar Organisation: This scheme prokles interconnection of n processor and n memory modules using switch elements. Switch element is having electronic circuit to provide desired path it supports priority logic to resolve conflicts. The interconnections of three processor with three memory modules have been in figure. Since each memory module have separate path. That means all memory modules can communicate at the same time. The hardware implementation is comparatively complex as compared to earlier scheme. 4. Multistage Interconnection Network : This scheme is having more than one stages of electronics switches. These stages provide the path between processor and memory modules. Each switch is having two inputs and two outputs. It is cost effective solution. Omega switching network is a popular example of this schemes. 5. Multiport memory : This scheme distributes the control, switching and priority arbitration logic throughout the crossbar switch. Priority logic in used to resolve memory conflicts. The control and switching logic is implemented in memory. Hence specialized memories are required. This scheme provides very high data transfer rate. Q. Write a short note on: (A) Parallel computing. (b) Distributed computing. (c) Serial and parallel interface. Ans. (a) Parallel computing : Parallel computing provides simultaneous data processing to increase the computation seed of computer. The important goal of computer architecture is to attain high performance. Implementing parallelism in uniprocessed or multiple processors can enhance the performance of computer. The concurrency in uniprocessor or superscalar in terms of hardware and software implementation can lead to faster execution of program in computer. Real times applications require faster response from computer. There are three main techniques to implement in parallel processing: (a) Multiprocessor system. (b) Pipelining. (c) Vector processing or computing. (b) Distributed computing: In distributed system each processor has its own local memory rather than having a shared memory or a clock as in parallel system. The processor communicate with one another through various communication media such as telephone lines, highspeed buses etc. Such systems are referred as looselycoupled systems. The processors may be called as sites, workstations, minicomputers and large general purpose computers etc. There are several factors that causes for building such system (a) Resource sharing : Users who are sitting-at different location can share the resources such as a user who is at location., A can share the printer who is at location B or vice-versa (b) Computation speed : When a single computation job is divided into number of sub computational job than naturally it executes faster due concurrent execution. (c) Reliability: In this failure of one processor slows down the speed of system but if each system is assigned to perform a pre-specified task then failure of one system can halt the system. One way to overcome such problem is use an another processor. Who works as a backup processor. (d) Communication : Some programs at different sites need to exchange the information, so they communicate with one another via electronic mail. (c) Serial and parallel interface: In parallel interface there is parallel independent lines of data exist from the I/O part to the device. In addition to these lines a few other optional lines are needed to synchronize the transfer of data Serial interfaces have only a single data line for bit by bit data transfers. Any serial interface has a shift register that converts serial data into parallel and vice versa. Serial interfaces are used for longer distance communication and can be used to connect two computers or a computer and a remote device. A serial interface standard such as Rs 232 C allows for inter connection devices upto 50 meters apart. Two types of serial interfaces are Asynchronous serial interface and synchronous serial interface another type of large number of application, the analog information has to be converted to digital form for input to the computer system. Similarly, where the output to device has to be in form of voltage or current which varies smoothly, the digital output form needs to be converted into analog form. A variety of devices are needed to convert the physical quantities such as pressure, temperature, light intensity etc. into electrical signals. These converting devices are called transducers. The output of transducers is a smoothly varying electric signal and converted into discrete digital patterns by a device A/D (analog to digital) converters. Q. Write and explain types of parallel processor systems. Ans. Parallel processing is used to denote a large class of techniques that is used to provide simultaneous data processing tasks for purpose of increasing the computational speech of a computer system. The parallel processing system is able to perform concurrent data processing to achieve faster execution time. Parallel processor system follows the parallel processing techniques. Parallel processor computers are required to meet the demands of large scale computations in many scientific, engineering, military, medical, artificial intelligence and basic research areas. The following are some representative applications of parallel processing computer. Numerical weather forecasting, computational aerodynamics, finite element analysis, remote sensing application genetic engineering, computer asserted forro graphy and weapon research and defence. There are following types of parallel processors 1. Array processors. 2. Vector processor. 3. Processor in pipeline processing. 4. Multiprocessor. 1. Array processor: An array processor is a processor that performs a large arrays of data. The term is used to refer to two types of processors. An attached array processor is an auxiliary processor attached to a generalpurpose computer. It is intended to improve the performance of the host computer in specific task. An SIMD array processor is a processor that has a single instruction multiple data organisation. It manipulates vector instruction by mean of multiple functional units responding to. common instruction. An attached array processor is designed as a peripheral for a conventional host computer, and its purpose is to enhance the performance of the computer by providing vector processing for the application. An SIMD array processor is a computer with multiple processing units operating in parallel. The processing unit are synchronized to perform the same operation under the control unit. This provides single instruction multiple data stream organisation. A general block of diagram of array processor is shown in figure 2. It contains a set of identical processing elements (pEs), Each having a local memory (M). 2. Vector processor : The problem can a formulated in terms of vectors and matrixes that lend themselves to vector processing. Computers with vector processing capabilities are in demands in specialized applications. The following are representative application areas where vector processing is of utmost importance. 1. Long range weather forecasting. 2. Petroleum exploration. 3. Seismic data analysis. 4. Medical diagnosis. 5. Aerodynamics and space flight simulations. 6. Artificial intelligence and expert system. 7. Mapping the human genome. 8. Image processing. 3. Processor in pipelining : A pipeline is as a collection of processing segments through which binary information flows. Each segment performs partial processing dictated by the way the task is partitioned. The result obtained from the computation in each segment is transferred to the next segment in the pipeline. The final result is obtained after the data have passed through all segments. The sub populations performed in each segment of pipeline are as follows: 4. Multiprocessor: A multiprocessor system is having two or more processors. This type of system will have one master CPU to control all other processors. The other processor may be coprocessor or I/O processor. The main features of multiprocessor system is to share main memory or other resources by all processors. The basic characteristics of multiprocessor system is as specified ahead: (a) This system must have more than one processor. All these processor must have nearly identical processing capabilities. (b) All these processor must have common shared memory. (c) Processors share all I/O devices of other resources. (d) The system configuration can be enhanced at required increments at any point of time.







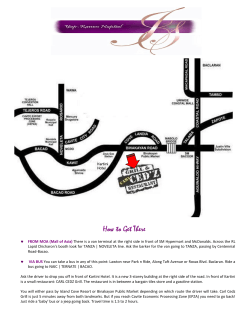


© Copyright 2026