
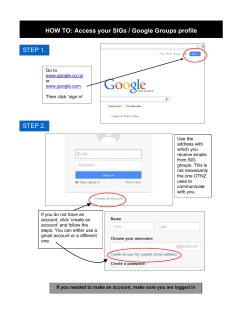
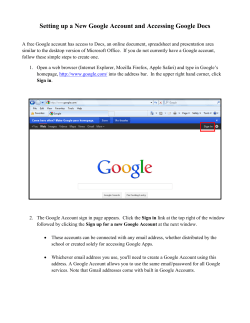
MapReduce What is MapReduce? • J. Walter Larson
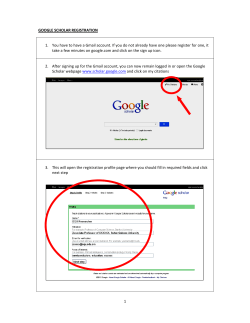
MapReduce
J. Walter Larson
Mathematical Sciences Institute
The Australian National University
What is MapReduce?
•
MapReduce is a programming model for generating/processing large
data sets
•
Two functional phases
•
•
•
•
Map - processes a key/value pair to generate an intermediate
representation that are also key/value pairs
•
•
Reduce - merges all intermediate values sharing the same key
Implementation’s run-time system library takes care of parallelism,
fault tolerance, data distribution, load balance, et cetera
Capable of efficiently processing TB’s of data on 1000’s of PEs
Used operationally at Google to generate various indices of WWW
Also the widely-used Hadoop open-source framework (Apache)
Or, Graphically...
Image Source: Google
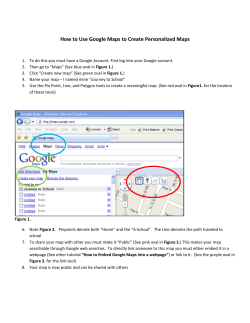
Parallelism in MapReduce
Image Source: Google
Programming Model
•
Express the computation as a composition of two functions--Map
and Reduce
•
Implement a Map() function to take input key/value pair and
transform it to the intermediate key/value pair
•
MapReduce library takes all intermediate key/value pairs, grouping
them by intermediate key, and subsequently passing them to the
user-defined Reduce() function
•
Implement a Reduce() function to take intermediate key and set of
associated values for it. This function merges these values to
produce (typically) just zero or one output value
•
•
Intermediate values typically supplied to Reduce() by an iterator
User also writes code to initialise MapReduce specification object
containing input/output file names and tuning parameters
Example: Word Counting
Map
Reduce
#include "mapreduce/mapreduce.h"
// User’s map function
class WordCounter : public Mapper {
public:
virtual void Map(const MapInput& input) {
const string& text = input.value();
const int n = text.size();
for (int i = 0; i < n; ) {
// Skip past leading whitespace
while ((i < n) && isspace(text[i]))
i++;
// Find word end
int start = i;
while ((i < n) && !isspace(text[i]))
i++;
if (start < i)
Emit(text.substr(start,i-start),"1");
}
}
};
REGISTER_MAPPER(WordCounter);
// User’s reduce function
class Adder : public Reducer {
virtual void Reduce(ReduceInput* input) {
// Iterate over all entries with the
// same key and add the values
int64 value = 0;
while (!input->done()) {
value += StringToInt(input->value());
input->NextValue();
}
// Emit sum for input->key()
Emit(IntToString(value));
}
};
REGISTER_REDUCER(Adder);
Registers functions
with framework
Main Program
int main(int argc, char** argv) {
ParseCommandLineFlags(argc, argv);
// Optional: do partial sums within map
// tasks to save network bandwidth
out->set_combiner_class("Adder");
MapReduceSpecification spec;
// Tuning parameters: use at most 2000
// machines and 100 MB of memory per task
spec.set_machines(2000);
spec.set_map_megabytes(100);
spec.set_reduce_megabytes(100);
// Store list of input files into "spec"
for (int i = 1; i < argc; i++) {
MapReduceInput* input = spec.add_input();
input->set_format("text");
input->set_filepattern(argv[i]);
input->set_mapper_class("WordCounter");
}
// Specify the output files:
// /gfs/test/freq-00000-of-00100
// /gfs/test/freq-00001-of-00100
// ...
MapReduceOutput* out = spec.output();
out->set_filebase("/gfs/test/freq");
out->set_num_tasks(100);
out->set_format("text");
out->set_reducer_class("Adder");
// Now run it
MapReduceResult result;
if (!MapReduce(spec, &result)) abort();
// Done: ’result’ structure contains info
// about counters, time taken, number of
// machines used, etc.
return 0;
}
Some Examples
• Distributed Grep: Map() emits line if a specific
pattern is matched; Reduce() copies intermediate
value to output
• Count of URL Access Frequency: Map() processes
web page request logs, outputting <URL, 1>;
Reduce() adds up corresponding URL values, emitting
<URL, total count>
• Reverse Web-Link Graph: Map() produces <target,
source> for link to target page from source page;
Reduce() emits <target, list(sources)>
Some Examples
•
Term-Vector per Host: Map() emits <hostname, term
vector> pairs for each document; Reduce() takes all these
pairs per host, adds them, retains the most frequent terms,
and emits reduced <hostname, term vector>
•
Inverted Index: Map() processes a set of documents emitting
<word, document ID> pairs; Reduce() accepts all pairs for a
given word, emitting <word, list(Document IDs)>
•
Distributed Sort: Map() extracts key for each record,
forming pair <key, record>; Reduce() emits all pairs
unchanged
Google’s Reference Implementation
•
Target platform: clusters of commodity PC with switched
ethernet
•
•
Typically dual-processor x86, 2-4GB RAM, Linux
•
•
•
O(1000) machines, so fault-tolerance is needed
•
•
Jobs submitted via a scheduling system
Gigabit ethernet, but cluster-wide the bisection bandwidth
will be lower
Storage is IDE disks attached to individual machines
Google’s DFS used to manage distributed data, providing
replication for availability and redundancy
C++ Library user links in to their programs
MapReduce Covers Shaded Area
Image Source: Google
MapReduce Covers Shaded Area
Image Source: Google
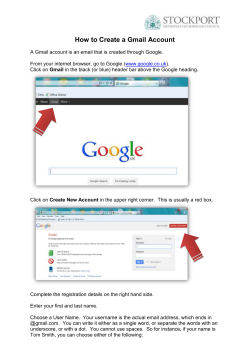
What happens at runtime?
(1) Create Splits of input files and start
set of tasks running copies of program
(3) Worker assigned a Map
task reads data from the task’s
corresponding split, parsing
key/value pairs from input and
passing them to Map()
(2) One task is the Master, the others
Workers. Master assigns Map and
Reduce tasks to idle workers
(5) Reduce worker is notified of
locations of intermediate key/value
pairs by Master, and uses RPC to get
the data from the corresponding Map
worker. Upon getting all these data,
perform sort on intermediate keys
(4) Periodic local writes, partitioned into R
regions by the partitioning function. Location
(6) Reduce worker iterates over sorted
of buffered pairs passed back to Master
intermediate data, passing data grouped by
key to Reduce(). Output of Reduce() is
appended to worker’s output file
(7) Upon completion of all Reduce tasks,
Master returns control to user program
Image Source: Dean and Ghemawat (2004)
More About the Master
•
Master owns several data structures to keep track of
execution
•
Stores state (idle, in-progress, completed) for each task, and
identity of worker machine for in-progress and completed
tasks
•
Master keeps track of location of intermediate file regions,
serving as conduit from Map to corresponding Reduce tasks
•
Updates are received from Map tasks as they are completed
by assigned Map workers; corresponding information pushed
incrementally to workers with in-progress Reduce tasks
Reproducibility
• When Map() and Reduce() are deterministic
with respect to their respective inputs,
results are the same regardless of numbers
of hosts
Data Locality
• Network bandwidth is valuable and
something one wants to spend wisely
• GFS replicates data (the paper claims
typically three copies) across the host farm
• The Master takes these locations into
account when scheduling Map tasks, trying
to place them with the data.
• Otherwise, Map tasks are scheduled to
reside “near” a replica of the data (e.g., on
the same network switch)
•
•
•
•
Granularity
Better load balance, but also about minimizing time for fault recovery
Opportunity to pipeline shuffling with Map
Typically 200k Map tasks, 5k Reduce tasks for 2k hosts
For M map tasks and R reduce tasks there are O(M+R) scheduling
decisions and O(M*R) states
Image Source: Google
Load Balance
•
•
The system already has dynamic load balancing built in
•
When an overall MapReduce operation passes some point
deemed to be “nearly complete,” the Master schedules
backup tasks for all of the currently in-progress tasks
•
When a particular task is completed, whether it be
“original” or back-up, its value is used
•
This strategy costs little more overall, but can result in big
performance gains
One other problem that can slow calculations is the
existence of stragglers; machines suffering from either
hardware defects, contention for resources with other
applications, et cetera
Fault Tolerance
•
•
Re-execute workload lost when a worker fails
•
Master marks as ‘idle’ both completed and in-progress Map tasks for
the failed worker (i.e., all of its work is re-done)
•
Reduce tasks reliant on failed Map worker are informed of new
locations of data they have not yet read
•
Master marks as ‘idle’ in-progress Reduce tasks for the failed worker;
it’s ‘completed’ work is already resident in a global file system
•
•
Task completion committed through master
Each worker is pinged periodically by the master; failure to respond
within a certain time results in master marking this worker as ‘failed’
Master failure another issue
What if the Master Fails?
• Checkpointing the Master’s state is a risk mitigation
strategy
• In event of Master failure, a new Master can be
started from the last checkpoint
• Not in Google implementation; given a single
Master among thousands of tasks, its failure is
unlikely
• Instead, system aborts in event of Master failure
Refinements
• Partitioning Function - default is “hash(key) mod R”
User can provide another one (e.g., sort URLs by
hostname)
• Ordering Guarantees - intermediate key/value pairs
are processed in increasing key order
• Combiner Function - user can specify an on-
processor function to combine Map output locally
before forwarding
• Input/Output Types - multiple supported; user can
also implement by coding to reader/writer interface
Refinements, Cont’d
•
Skipping Bad Records - MapReduce provides a mode for
skipping records that are diagnosed to cause Map() crashes
•
Local Execution/Debugging - Alternative implementation of
MapReduce library to support executes sequentially on one
host
•
Status Information - Master contains internal http server to
produce status pages that allow a user to monitor progress
and accelerate it by adding more hosts
•
Counters - User code creates named counter object and
increments in Map()/Reduce()
Runtime Narrative
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Image Source: Google
Benchmarks
•
•
MR_Grep: Scan 10^10
100 byte records looking
for a rare pattern present
in only 92k records
MR_Sort: Sort 10^10
100 byte records
(modeled on TeraSort
benchmark)
•
Hardware
•
•
1800 machines
•
•
•
4GB RAM
dual processor 2GHz
Xeons
Dual 160GB IDE disks
Bisection BW approx.
100Gbps
MR_Grep
• 1800 Machines read data at peak 31GB/s
• Rack switches would limit to 10GB/s
Image Source: Google
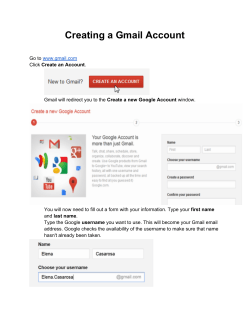
MR_Sort
Normal
No Backup Tasks
200 PEs Killed
Image Source: Google
Impact
• Google have rewritten their production indexing
system using MapReduce as a set of 24 MapReduce
operations
• New code is simpler and easier to understand
• New suite provides more even performance and
fault-tolerance
• Easier to make indexing faster simply by adding
more machines!
Acknowledgments
• The material in this lecture was taken from two
sources
• J. Dean and S. Ghemawat (2004)“MapReduce:
Simplified Data Processing on Large Clusters,”
Proceedings Sixth Symposium on Operating System
Design and Implementation.
• Lecture Slides associated with the above paper
• Both available from Google Lab’s web site at
http://labs.google.com/papers/mapreduce.html






© Copyright 2026